
Posts in category Wiskunde
Het laatste cijfer
Op twitter werd gevraagd naar het laatste cijfer van het getal van Graham. Grappig genoeg heeft dat een redelijk eenvoudig antwoord.
In deze coronatijden krijgen ouders vragen van hun kinderen die deze meestal aan de onderwijzer(es) vragen, zoals
waarom eindigt dat op een 7, en niet op een 9 of een 0? Daar hield onze lokale kennis op, dus hopelijk weet jij raad @ionicasmeets ?
— Mirjam070 (@MvL070) April 5, 2020
Nu is het getal van Graham het resultaat van een ongelooflijk aantal malen machten van 3 nemen, in een toren van 3-en. Het resulterende getal is nog groter. Maar hoe zou je het laatste cijfer van dat getal kunnen bepalen? Dat is eenvoudiger dan het lijkt. We doen het in stappen.
Om te beginnen het getal is een macht van 3 en als we de eerste paar machten van 3 opschrijven, en alleen het laatste cijfer noteren vinden we 3, 9, 7, 1, 3, 9, 7, 1, … Dat dit zich zo blijft herhalen wordt duidelijk als je je realiseert dat het laatste cijfer van 3×n alleen van het laatste cijfer van n afhangt.
Welke van die vier cijfers is het nu? Welnu de exponent van het getal is weer een macht van drie en dus oneven. Dat betekent dat we alleen een 3 of een 7 als mogelijkheid overhouden. Als we van die exponent de rest kunnen vinden bij deling door 4 weten we welk van de twee het is.
Schrijf die resten maar op: 31 heeft rest 3; 32 heeft rest 1; 33 heeft rest 3; 34 heeft rest 1; … het patroon wordt duidelijk: bij oneven exponenten is het 1 en bij oneven exponenten is het 3.
Maar we hebben een toren van drieën, dus de exponent van de exponent is oneven en het eindcijfer is gelijk aan 7.
Iets geavanceerder
Als je hebt leren rekenen modulo getallen (`klokrekenen’) gaat het sneller.
Onze vondst van periode 4 vind je door te zeggen 31=3,
32=9, 33=27=7 modulo 10, 34=3×7=21=1 modulo 10 en zodra we 1 hebben gevonden is duidelijk dat we de periode hebben.
Dan moeten we modulo 4 rekenen om te weten of we 3 of 7 krijgen, maar 3=-1 modulo 4, dus 3k=(-1)k modulo 4 en dan is duidelijk wat we krijgen bij een oneven exponent.
Opgave
Probeer zelf de laatste twee cijfers van het getal van Graham te bepalen. Het duurt iets langer maar met een beetje volhouden kom je er wel.
Continuïteitsmaximalisatie
Op twitter, via Japka-d. Bouma, een mooi woord gevonden: continuïteitsmaximalisatie. Ik vroeg me meteen af of ik daar wiskundig chocola van kon maken.
Hier is de tweet waar het mee begon.
Dit woord is samen met Scrabble bedacht: 'continuïteitsmaximalisatieprogramma'. https://t.co/ipPPU6WsKo
— Japke-d. Bouma (@Japked) December 9, 2019
Op het eerste gezicht lijkt er aan continuïteit weinig te maximaliseren: een functie is continu of niet en daar is de kous mee af, lijkt het. Maar de situatie waar het in de tweet om gaat wijst in een richting waar de ene continuïteit beter is dan de andere. Het gaat er om een overname van een bedrijf zo goed mogelijk te laten verlopen.
Natuurlijk wil je bij een overname geen plotselinge sprongen zien; dat komt overeen met het wiskundige idee van continuïteit: het traject van de opvolger begint waar dat van de voorganger stopt. Maar dat is niet genoeg; de grafiek van de absolute-waardefunctie laat zien wat in de praktijk wat ongewenst is: een plotselinge verandering van richting.
De trajecten moeten glad aansluiten (`glad’ is eigenlijk een beter woord dan `continu’, gladheidsmaximalisatie dus); de aansluiting moet differentieerbaar verlopen. Maar, een plotse verandering van snelheid is ook niet prettig; dus de snelheid ook maar glad (differentieerbaar) houden dus (continue versnelling). Wat men zich echter niet realiseert is dat de derde afgeleide, de afgeleide van de versnelling dus, ook niet al te veel moet veriëren: die derde afgeleide heet de jerk (de ruk) van een beweging en is veelal de hoofdoorzak van misselijkheid.
Zo kunnen we natuurlijk door blijven gaan en steeds meer gladheid eisen. Dan komt er van maximalisatie niet veel terecht. Maar er is wel een maximum te benoemen. In eerste instantie zou je zeggen dat oneindig vaak differentieerbaar toch wel het beste is wat gehaald kan worden. Er is zo’n mooie overgang: definieer f(x)=0 voor x≤0, en voor x>0 nemen we f(x)=exp(-1/x); een plaatje van de grafiek voor x tussen 0 en 1 op Wolfram Alpha laat zien dat hier inderdaad een zeer gladde overgang bereikt wordt. Deze functie is inderdaad superglad: oneindig vaak differentieerbaar in 0.
Is dat het maximaal haalbare? Nee, onder de supergladde functies zijn er die extra-superglad zijn: de analytische functies; daar is de functie hierboven er niet een van. Analytische functies zijn de echte continuïteitsmaximaliseerders en de meeste functies die mooi lijken zijn het ook: de sinus, de cosinus, de e-macht, de wortel, … allemaal analytisch.
Lariekoek? I
Dit is de vierde in een korte serie blogposts naar aanleiding van een discussie op twitter over dit stuk op Neerlandistiek.nl van Marc van Oostendorp dat zelf weer een reactie op dit artikel van Paul Postal was. In de eerste post kwalificeerde ik een opmerking uit het stuk van Postal als lariekoek. Daar gaat deze post over.
De opmerking van Postal betreft de grootte van de `collectie’ van alle boeken in een taal. Die collectie is niet alleen oneindig groot, niet alleen overaftelbaar, maar zelfs groter dan elke denkbare verzameling. Voor (een idee van) het bewijs van deze bewering verwijst Postal naar het artikel Sets and Sentences en een boek, The Vastness of Natural Languages, beide geschreven door hemzelf en D. Terrence Langendoen.
Ik heb wat met verzamelingen en wilde daarom wel eens zien waarom de collectie boeken in een Natuurlijke Taal zo groot moest zijn. Het boek heb ik niet te pakken kunnen krijgen maar deze recensie beweert dat de kern van de inhoud al in het artikel staat. laten we dat artikel dan maar eens bekijken.
Het artikel bestaat uit drie delen: een korte inleiding, een deel waarin “naar analogie met Cantors’s resultaten” wordt beargumenteerd dat de zinnen in een natuurlijke taal geen verzameling vormen, en een deel met conclusies.
Dat tweede deel begint met wat definities die het beschrijven van constructies van nieuwe `zinnen’ uit oude mogelijk moeten maken. Het hoofdingrediënt is dat van een conjunct, dat is een eenheid die bestaat uit een connectief en een deelconjuct. Die conjuncties kunnen in/tot `co-ordinate compound constituents’ samengevoegd worden. Zo’n co-ordinate compound moet wel echt `compound’ zijn en dus uit ten minste twee conjuncten gevormd worden.
Vervolgens spreken de schrijvers af hoe uit een verzameling U van constituents een co-ordinate compound constituent T gemaakt kan worden; of beter: hoe we kunnen zien dat T uit U gemaakt is. Elke conjuct in T heeft een element van U als deelconjunct, elk element van U is deelconjunct van precies één conjuct van T, en de conjuncten in T zijn geordend (daarover later meer).
In dit geval is T een `co-ordinate projection‘ van U, en U is de `projection set van T. Let op het gebruik van `een’ en `de’ in de vorige zin.
Ik kan begrijpen dat dit allemaal nogal abstract overkomt en ik moest het zelf een paar keer lezen voor ik dacht door te hebben wat er aan de hand is. Achter al die termen zitten plaatjes als het onderstaande verscholen:
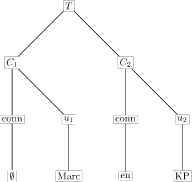
De verzameling U bestaat uit de constituents `Marc’ en `KP’; uit elk element van U kunnen we een conjunct maken door er een connectief aan vast te plakken. Dat connectief kan leeg zijn, zoals bij `Marc’ omdat, bijvoorbeeld, je aan het begin van een zin geen voegwoord gebruikt en toch iets nodig hebt om je conjuct te markeren. Daar nemen we dan ∅ maar voor. In de woorden van Langendoen en Postal: C1 en C2 zijn de dochters van T, die zusters zijn elk een conjuct, bestaande uit een connectief en een deelconjuct.
De hoofdaanname, of het hoofdaxioma, is nu dat elke verzameling constituents tot een co-ordinate compound constituent gevormd kan worden. De (co-ordinate compound) constituents waar we het verder over zullen hebben zijn gewoon zinnen, en daarom zal ik ze verder ook maar zo noemen.
Om te beginnen maken we oneindig veel zinnen:
- De reële rechte is overaftelbaar
- Ik weet dat de reële rechte overaftelbaar is
- Ik weet dat ik weet dat de reële rechte overaftelbaar is
- Ik weet dat ik weet dat ik weet dat de reële rechte overaftelbaar is
- …
Niet erg opwindende zinnen maar daar gaat het niet om: er is een duidelijke procedure die voor elk natuurlijk getal n een zin Z(n) construeert. Dit is een voorbeeld van een recursieve definitie: als we een beginobject beschrijven en een recept aangeven om elk volgende object te maken dan beschouwen we de constructie als voltooid.
Voor elke deelverzameling U van deze verzameling {Z(n):n∈N} van zinnen bestaat er dus een zin waarvan de deelconjucten precies de zinnen uit U zijn. Dat geeft ons dan overaftelbaar veel zinnen.
Daarmee is het hek van de dam: we kunnen blijven doorgaan en elke deelverzameling van de nieuwe verzameling zinnen weer samensmeden tot een nieuwe zin. En weer, en weer, en weer, …
De conclusie van Langendoen en Postal is nu dat alle zinnen die we zo kunnen maken geen verzameling vormen. Hier komt de analogie met Cantor’s resultaten om de hoek kijken. Cantor bewees namelijk dat elke verzameling strikt meer deelverzamelingen heeft dan elementen. Als je dit toepast op `de verzameling van alle verzamelingen’ kom je in de knoop: de elementen van die `verzameling’ zijn precies zijn deelverzamelingen, maar dat kan niet omdat er meer deelverzamelingen dan elementen zijn. De entiteit `de verzameling van alle verzamelingen’ bestaat dus niet.
Dezelfde redenering is nu van toepassing op `de verzameling van alle zinnen in een natuurlijke taal’: elke deelverzameling bepaalt een zin en verschillende deelverzamelingen bepalen verschillende zinnen en dat druist in tegen de conclusie van Cantor: altijd strikt meer deelverzamelingen dan elementen.
Waarom Lariekoek?
Waarom denk ik dat dit lariekoek is? Dat heeft vooral te maken met de manier waarop Langendoen en Postal hun `bewijs’ presenteren. Daar is wiskundig veel op af te dingen. Maar deze post is al behoorlijk lang en ik bewaar mijn wiskundige opmerkingen, bijvoorbeeld over de bovengenoemde ordeningen daarom maar voor deel twee.
Getallen bestaan (eigenlijk) niet
Dit is de derde in een korte serie blogposts naar aanleiding van een discussie op twitter over dit stuk op Neerlandistiek.nl van Marc van Oostendorp dat zelf weer een rectaie op dit artikel van Paul Postal was. De eerdere delen staan hier en hier.
Tussen al die tweets maakte ik de volgende opmerkingen:
Daar komt nog bij dat `getal' als aantal’ strikt genomen gedefinieerd moet worden; verzamelingen hebben geen intrinsiek `aantal elementen'. Boeken zijn inderdaad eerder stellingen. https://t.co/Mjjth2qDKd
— (((K P Hart))) (@hartkp) October 15, 2019
Daar wil ik het vandaag even over hebben. Wat zijn getallen eigenlijk? Die vraag werd zelfs op de Nationale Wetenschapsagenda gesteld en ik heb daar al eens een antwoord op gegeven. Ik wil dat hier wat uitgebreider doen.
Getallen
Om te beginnen: in de discussie en de stukken ging het over natuurlijke getallen en die werden vereenzelvigd met hun decimale schrijfwijze. Dat is, in deze tijd, heel natuurlijk: afgezien van jaartallen in Romeinse notatie op gevels van gebouwen (en als paginanummers in boeken vóór de echte inhoud begint) zien we getallen eigenlijk alleen opgeschreven met behulp van de indo-arabische cijfers en de positionele schrijfwijze.
Gegeven deze vereenzelviging is er wel iets te zeggen voor het idee dat boeken en getallen iets gemeen hebben: rijen symbolen met een welgedefinieerde inhoud.
Aan de andere kant: getallen zijn in zekere zin absoluut: ze zijn bestand tegen vertalingen. Twaalf, twelve, douze, tolv, dvanást’, teyan-a-bub, … verwijzen allemaal naar exact dezelfde hoeveelheid streepjes: ||||||||||||.
Als ik een stuk tekst van mezelf in het Engels vertaal is die exactheid weg. Sommige nederlandse woorden en uitdrukkingen doen het niet zo goed in letterlijke vertaling (“laat maar” versus “let but”) en een equivalent-bij-benadering is slechts dat: een benadering. Vergelijk deze twee stukken over de Gulden Snede maar: nederlands versus engels.
Meer, minder, even veel
Maar goed, terug naar de vraag over de aard, of het bestaan, van getallen. Ik denk/vind dat getallen, in de zin van aantallen, niet bestaan.
“Maar we tellen toch dagelijks dingen”, hoor ik u zeggen. Inderdaad, maar de zaken die we daarbij gebruiken zijn bedacht, ze bestaan niet in het wild. Ooit `het getal dat wij in het Nederlands drie noemen’ gezien? En hierbij wel de gebruikelijke notaties loslaten, het symbool 3 telt niet, en III ook niet, en γ’ ook niet.
Maar er is meer: in de verzamelingenleer is het na invoering van de bekende soorten afbeeldingen, injectief, surjectie, en bijectie een koud kunstje te definiëren wanneer de ene verzameling minder, meer, of even veel elementen heeft als een andere. Kleine kinderen weten dat al heel snel, en zonder tellen: haal uit beider zakje snoepjes telkens tegelijkertijd één snoepje. Het zakje dat het eerst leeg is bevatte minder snoepjes dan het andere en gelijk leegraken betekent even veel. Probeer het zelf maar eens: neem twee lepels hagelslag en zoek zo uit welke lepel de meeste korrels heeft.
Maar als je in de verzamelingen een antwoord wilt geven op de vraag “Hoeveel elementen?” sta je in het begin met de mond vol tanden. Na vrij veel werk lukt het een klasse van standaardverzamelingen af te zonderen waarmee andere verzamelingen gemeten kunnen worden en zo een `aantal elementen’ opgeplakt kunnen krijgen. Dat wil zeggen: dit werkt voor eindige verzamelingen, waarbij `eindig’ zo wordt gedefinieerd dat `het’ ook inderdaad werkt.
Hoeveel?
Hoe zit het met willekeurige verzamelingen? Georg Cantor dacht dat er zoiets als `het aantal elementen’ moest zijn; hij had zelfs een definitie:
,Mächtigkeit` oder ,Cardinalzahl` von M nennen wir den Allgemeinbegriff, welcher mit Hülfe unseres activen Denkvermögens dadurch aus der Menge M hervorgeht, dass von der Beschaffenheit ihrer verschiedenen Elemente m und von der Ordnung ihres Gegebenseins abstrahirt wird.
Uit die definitie halen we de volgende eisen waar dat Kardinaalgetal C(M) aan zou moeten voldoen:
- M en C(M) hebben even veel elementen (als bij de zakjes snoep), in vaktaal: er is een bijectie tussen M en C(M) — C(M) is dus ook een verzameling
- als er tussen M en N een bijectie bestaan dan C(M)=C(N)
Als er dus zo’n functie is dan kunnen we C(M) `het aantal elementen’ van M noemen.
En, helaas, zo’n functie kun je niet definiëren. Het bewijs van die ondefinieerbaarheid hoop ik maandag 16 december tijdens het laatste college van de Mastermath-cursus Set Theory af te ronden.
Wat betekent dit? Dat verzamelingen geen `intrinsiek’ aantal elementen hebben. Je kunt niet meer doen dan zelf een hoeveelheid standaardverzamelingen af te spreken waarmee je op zinvolle wijze betekenis aan `het aantal elementen’ kunt geven. Getallen zijn geen natuurverschijnselen maar mensenwerk.
Dit gebeurde vaker
De vraag wie van twee mensen langer of korter is is zo beantwoord: hou ze tegen elkaar aan en je ziet het. Om de vraag “Hoe lang zijn die twee mensen?” te beantwoorden zijn in de loop der tijd veel systemen bedacht, sommigen wat logischer dan de andere. Ons metrieke stelsel is overgebleven, ongetwijfeld door de voor de hand liggende definitie van de meter: neem de halve meridiaan van de noordpool door Parijs naar de evenaar en hak die in 10.000.000 even grote stukjes; elk stukje is, per definitie, één meter lang.
Oh, en `teyan-a-bub’? Dat gebruik je bij het tellen van schapen in Weardale.
KP checkt: Hartslag en de Gulden Snede
In deze blogpost beschreef ik een artikel waarin metingen aan mensenschedels moesten aantonen dat een aantal maten zich volgens de Gulden Snede zouden verhouden. De conclusies waren nogal discutabel maar ook al waren de getallen niet echt dicht bij de Gulden Snede ze leken tenminste te kloppen. In de referenties van het artikel vond ik veel verwijzingen naar andere voorkomens van de Gulden Snede. Twee daarvan heb ik nader bekeken: Golden Ratio is beating in our heart en Does systolic and diastolic blood pressure follow Golden Ratio. Daar kloppen de getallen iets minder goed.
Kloppende getallen
Wat bedoel ik met `kloppende getallen’? Welnu, als je een lengte, zeg A, in twee stukken verdeeld, zeg B en C, dan geldt natuurlijk A=B+C. Als je op jacht bent naar de Gulden Snede neem je de grootste van de twee stukken, zeg C, en dan bekijk je de verhoudingen A/C en C/B. Je hoopt dat die verhoudingen gelijk zijn want dan heb je de Gulden Snede te pakken.
Tussen die twee verhoudingen bestaat een relatie: deel de gelijkheid maar door C dan krijg je A/C=B/C+1, of iets ingewikkelder opgeschreven: A/C=1/(C/B)+1. Als we onze twee verhoudingen even afkorten, A/C=y en C/B=x, dan staat hier y=1/x+1.
Anders gezegd: het punt met coordinaten (C/B,A/C) ligt op de grafiek van y=1/x+1.
In het artikel Mammalian Skull Dimensions and the Golden Ratio worden de volgende gemiddelden van de verhoudingen gerapporteerd: A/C=1.64 ± 0.04) en C/B=1.57 ± 0.10 (de letters zijn anders, maar het gaat om de getallen).
Niet alleen het punt (1.57,1.64) ligt op de grafiek van y=1/x+1 maar ook de punten (1.47,1.68) en (1.67,1.60); deze worden bepaald door de randpunten van de intervallen (1.60,1.68) (voor A/C) en (1.47,1.67) (voor (C/B). Zie het plaatje hieronder.
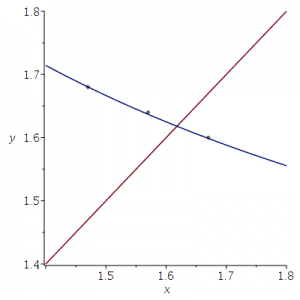
Dit bedoel ik met kloppende getallen: de resultaten horen in ieder geval bij de stituatie waar A=B+C.
Overigens laat ik het aan de lezer om te beoordelen, gezien dit plaatje, in hoeverre deze conclusie gerechtvaardigd is:
In humans, the ratio of the nasioiniac arc over the parieto-occipital arc (NI/BI = 1.64 ± 0.04) and the ratio of the parieto-occipital arc over the frontal arc (BI/NB = 1.57 ± 0.10) are essentially identical and closely approximate Φ (1.618) within 1 standard deviation.
Het snijpunt van de twee grafieken (y=1/x+1 en y=x) is het punt (Φ,Φ), en daar ligt (1.57,1.64) toch nog wel ver vandaan.
Hartslag en bloeddruk
In de referenties van het schedelartikel vond ik de artikelen die hierboven genoemd werden.
Hartslag
Om te beginnen: in Golden Ratio is beating in our heart wordt de Gulden Snede ontdekt in verhoudingen van tijdsintervallen in de hartslag. Een mooi plaatje met een uitleg van alle termen staat op de wikipedia-pagina over het QRS-complex:

De drie grootheden waar het hier om gaat zijn: (A) het R-R-interval (tussen twee opeenvolgende R-en), (B) de systole (samentrekfase), en (C) de diastole (ontspanningfase).
De letters komen overeen met onze eerste paragraaf en met de verhoudingen waar het artikel over gaat.
De resultaten zijn
- A=866 ± 73
- B=333 ± 22
- C=536 ± 66
- C/B=1.611
- A/C=1.618
Deze getallen zijn problematisch.
Ten eerste tellen de gemiddelde waarden niet goed op: A=866 en B+C=869. Dat zou wel moeten als alle metingen goed waren dan geldt A=B+C voor elke meting en dan ook voor de gemiddelden.
Ten tweede: als een van de verhoudingen gelijk is aan Φ dan is de andere dat ook, hier is dat niet zo.
Ten derde: als je, net als in het schedelmetingartikel, de verhoudingen van de gemiddelden neemt kom je op andere getallen uit: 866/536=1.61567 en 536/333=1.6096.
Het zou kunnen zijn dat de gerapporteerde verhoudingen gemiddelden zijn van de verhoudingen per meting maar dan hadden de auteurs dat wel even mogen vermelden.
Voorlopig geloof ik niets van de conclusies van het artikel.
Het lijkt er op dat de individuele verhoudingen wel zijn uitgerekend want het artikel bevat nog een niet-ter-zake-doende grafiek waarin de verhouding C/B is uitgezet tegen de hartslag.

Daar is in ieder geval te zien dat de verhouding C/B behoorlijk variabel is.
Bloeddruk
In het artikel Does systolic and diastolic blood pressure follow Golden Ratio gaat het om de bloeddruk. De grootheden zijn nu: (A) de systolische druk (bovendruk), (C) de diastolische druk (onderdruk), en (B) hun verschil; alle in mm Hg.
| A | C | B | A/C=y | C/B=x | |
|---|---|---|---|---|---|
| etmaal | 137 ± 16 | 86 ± 12 | 51 | 1.59 | 1.69 |
| dag | 140 ± 17 | 89 ± 12 | 51 | 1.57 | 1.75 |
| nacht | 131 ± 18 | 80 ± 13 | 51 | 1.64 | 1.62 |
Wat hier opvalt is dat er voor het verschil geen interval is opgegeven; alsof het bij alle metingen precies 51 mm Hg was (dat geloof ik dus niet). De verhoudingen komen hier wel voort uit de gemiddelden behalve de verhouding C/B in de nacht: 80/51=1.56862. Laat die foute 1.62 nou net de verhouding zijn die het dichtst bij de Gulden Snede ligt.
Ik heb de punten vergeleken met de grafiek van y=1/x+1.
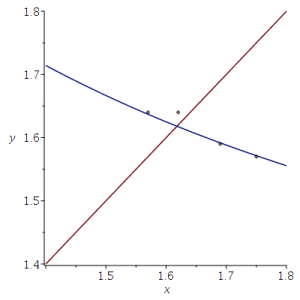
De twee punten rechts horen bij de verhoudingen voor een etmaal en overdag. Het meest linkse punt hoort bij de echte nachtelijke verhoudingen. Het punt dat ruim boven de grafiek ligt hoort bij de gerapporteerde nachtelijke verhoudingen. Ik heb geen idee hoe dat gebeurd kan zijn.
Daar is-tie weer: de Gulden Snede
Niet uit te roeien, die Gulden Snede: via een stukje op Science Alert kwam ik hier: Mammalian Skull Dimensions and the Golden Ratio.
Wat staat er in dat artikel?
Welnu over je schedel loopt een lijn, van het Nasion (N) naar het Inion (I); op die lijn ligt een punt het Bregma (B) geheten. Op honderd mensenschedels zijn de lengten NI, NB en BI gemeten (niet letterlijk, er is gemeten aan hoge-resolutiescans van schedels). Nu geldt, natuurlijk, NB+BI=NI en verder is het deel BI wat groter dan het deel NB.
Op zoek naar de Gulden Snede hebben de auteurs van elke schedel de verhoudingen NI/BI en BI/NB bepaald. Als B de lijn NI inderdaad volgens uiterste en middelste reden verdeelt, dan verwachten we dat NI/BI gelijk is aan BI/NB.
Na middelen en standaard-deviatie nemen komen de auteurs uit op NI/BI = 1.64 ± 0.04 en BI/NB = 1.57 ± 0.10. In de woorden van de auteurs:
In humans, the ratio of the nasioiniac arc over the parieto-occipital arc (NI/BI = 1.64 ± 0.04) and the ratio of the parieto-occipital arc over the frontal arc (BI/NB = 1.57 ± 0.10) are essentially identical and closely approximate Φ (1.618) within 1 standard deviation.
Ik weet niet wat de lezer denkt maar in vind dat een krasse uitspraak. De gemiddelden liggen nogal ver uit elkaar. Of je nu vanuit 1.64 of vanuit 1.57 rekent, het verschil is relatief meer dan 4%. Dat lijkt me niet `essentially identical’. Ik denk dat de wens hier toch de vader van de gedachte is geweest.
Overigens zijn de opgegeven waarden wel consistent met de betrekking die tussen de verhoudingen moet gelden: door de gelijkheid NB+BI=NI door BI te delen ontstaat de gelijkheid NI/BI = 1/(BI/NB)+1. Om dit iets overzichtelijker te maken noemen we NI/BI even y en BI/NB even x, de gelijkheid wordt dan y=1+1/x. De punten (1.57,1.64), (1.47,1.68) en (1.67,1.60) liggen op een haar na op de grafiek van deze vergelijking.
Deze betrekking verklaart ook de volgende observatie van de auteurs:
Interestingly, the reciprocal of Φ (1/Φ or 1/1.61803…) is 1 integer less than Φ (0.61803…) and has the same decimal extension as Φ, and the square of Φ (Φ² or 1.61803…2) is 1 integer more than Φ (2.61803…) and also has the same decimal extension.
Uhm, ja, nogal wiedes; de verdeling in uiterste en middelste reden dicteert dat Φ aan de gelijkheid Φ=1+1/Φ moet voldoen, en dus ook aan Φ²=Φ+1. Iedere middelbare-scholier die kwadratische functies heeft gezien kan je dit uitleggen.
Ten slotte
Het artikel beslaat negen kolommen; daarvan zijn er vier gevuld met een verslag van de metingen; er is ook aan zes andere zoogdiersoorten gemeten en het lijkt er op dat bij toenemende `complexiteit’ van de soort de verhouding NI/BI daalt en BI/BN dus stijgt. De (speculatieve) uitleg is dat gaande de evolutie de schedel op deze manier bij bepaalde kwabben is gaan passen.
Als de auteurs zich nu maar bij deze conclusie hadden gehouden dan was er weing mis geweest met dit artikel. De overige vijf kolommen zijn echter gevuld met niet ter zake doende beschrijvingen van de Gulden Snede, de relatie met de rij van Fibonacci, en het vermeende optreden van dit getal bij allerlei fysiologische en morphologische verschijnselen.
Allerlei al lang onderuit gehaalde mythes over de Gulden Snede worden weer van stal gehaald en als belangwekkende feiten gepresenteerd.
In het fraaie boek De Ontstelling van Pythagoras heeft Albert van der Schoot vrijwel niets heel gelaten van alle flauwekul die over de Gulden Snede verteld wordt. De recensie in NRC noemt er al een paar. En lees ook het artikel Het is niet alles goud wat er snijdt van Van der Schoot in het Nieuw Archief voor Wiskunde.
Ook deze column van Keith Devlin is het lezen meer dan waard.
Metaforen? Liever definities.
Bij uitleg van niet-triviale wiskundige resultaten grijpt men nogal vaak naar een of andere metafoor, waarschijnlijk omdat de echte context te moeilijk voor de lezer wordt gevonden. Dat leidt vrijwel altijd tot onbegrip of erger nog tot slecht begrip. Een extreem voorbeeld was onlangs te vinden in NewScientist.
In bovenvermeld stuk werd melding gemaakt van een, ook voor de gemiddelde wiskundige, niet-triviaal resultaat — de formulering was in de vorm van een metafoor over een oneindige versie van de lotto. Die was zo onduidelijk dat ik aan het eind van het stuk nog steeds niet wist niet wat het wiskundige resultaat was (of zelfs waar het over ging); pas na doorklikken naar het echte artikel herkende ik het als iets dat ik in april al voorbij had zien komen. De reacties onder het stuk laten zien dat er meer lezers waren die niet begrepen hadden waar het over ging.
Nadat ik mijn blogposts (deze en deze) op facebook had gezet schreef een collega dat de opsteller van het oorspronkelijke probleem (Adrian Mathias) zelf de lotto-metafoor had verzonnen.
Het probleem van het stuk in NewScientist (en het het origineel) was ook nog dat de uitleg niet volledig was: het was niet duidelijk hoe de lottoformulieren in te vullen en er werd al helemaal niet vermeld hoe je zou kunnen winnen.
Ik heb zelf maar een lotto verzonnen en aan twitter gevraagd welke uitleg beter was: zakelijk of metaforisch.
Welke uitleg is beter
— (((K P Hart))) (@hartkp) September 20, 2019
De uitslag was overweldigend: 100% vond de zakelijke uitleg beter. Ik geef toe: drie stemmen is niet veel, maar er moest dan ook wel veel gelezen worden.
Het wiskundige resultaat ging over families oneindige deelverzamelingen van de verzamelingen der natuurlijke getallen. In deze blogpost staat meer informatie; het kost waarschijnlijk enige moeite alles te verstouwen maar ik heb de illusie dat heze uitleg beter is dan een gekunstelt verhaal over de lotto.
Het oneindige fascineert velen, dat is zelfs te zien geweest in de Nationale Wetenschapsagenda. Veel vragen gingen eigenlijk over de metaforen die gebruikt zijn om `oneindig’ uit te leggen en hadden dus eigenlijk in het geheel geen wiskundige inhoud. En dat vind ik dus jammer. De wiskunde van het oneindige is te mooi om in verhullende verhalen te verstoppen. Wie mij over oneindig wil laten praten krijgt de definities om de oren (en het helpt als je vantevoren deze wikipediapagina goed bestudeert.
U bent gewaarschuwd.
Loterijen? Nou, nee.
Vanochtend (2019-09-19) vond ik via twitter dit artikel uit NewScientist (een vrij letterlijke vertaling van dit stuk. Nadat ik het verhaal over niet-bestaande oneindige loterijen had gelezen was ik nog niets wijzer geworden. Na doorklikken naar het originele artikel zag ik dat ik het al eerder had gezien in april, op ArXiV.org en dat het niets met loterijen te maken had.
Maar waar gaat het artikel dan wel over? Over bijna-disjuncte families. En wat zijn dat nu weer?
Eén van mijn favoriete objecten in de verzamelingenleer is de familie van alle deelverzamelingen van de verzameling N der natuurlijke getallen. Dit is een nimmer opdrogende bron van vragen en resultaten die in veel delen van de wiskunde gebruikt worden maar die gewoon ook leuk zijn om aan te werken.
Hierbij is het bijwoord `bijna’ bijna niet te vermijden. In het artikel waar we het hier over hebben past men `bijna’ dus toe op `disjunct’. Nu noemen we twee verzamelingen A en B `disjunct’ als hun doorsnede leeg is, A∩B=∅, als er geen x is die zowel in A als in B zit.
Het woord `bijna’ kort eigenlijk het wat uitgebreidere `op eindig veel na’ af: twee verzamelingen zijn bijna disjunct als hun doorsnede eindig is — `hun doorsnede is op eindig veel elementen na leeg’. Hierbij eisen we wel dat de verzamelingen zelf oneindig zijn want anders is bijna-disjunctheid niet zo spannend.
De twee verzamelingen E en O van respectievelijk de even en oneven getallen zijn disjunct; er is geen natuurlijk getal van tegelijk even en oneven is.
Hier is een mooie truc, van Sierpinski uit 1928: voor elk positief irrationaal getal x en voor elk natuurlijk getal n doen we het volgende: bepaal n×x, neem het gehele deel [n×x] (gooi alles achter de komma weg) en deel dat weer door n.
Bij vaste x krijg je zo een rij rationale getallen: [x], [2x]/2, [3x]/3, [4x]/4, … Bij π bijvoorbeeld krijgen we zo 3, 3, 3, 3, 3, 3, 3, 25/8, 28/9, 31/10, 34/11, 37/12, …
Uit de definitie van de rij volgt dat 0<x-[n×x]/n<1/n voor alle n en dit betekent iets voor de bijbehorende verzamelingen termen. Bij elke x stoppen we de termen van de rij in de verzameling Sx, dus Sπ={3, 25/8, 28/9, 31/10, 34/11, 37/12, …}.
Neem nu eens twee irrationale getallen x en y met x<y; dan geldt voor n>1/(y-x) dat [n×y]/n>y-1/n>x, en dus zit [n×y]/n niet in Sx. We concluderen dat de verzamelingen Sx en Sy bijna disjunct zijn.
De verzamelingen Sx vormen het soort familie waar het artikel over gaat: een bijna-disjuncte familie, elk tweetal elementen is bijna disjunct (en elke Sx heeft oneindig veel elementen).
Het voorbeeld van Sierpinski laat zien dat er een groot verschil is tussen `disjunct’ en `bijna disjunct’. Als een familie disjunct is dan zit elk punt in ten hoogste één element van de familie. De bijna-disjuncte familie van Sierpinski bestaat uit verzamelingen rationale getallen, daar zijn er evenveel van als natuurlijke getallen. De familie zelf heeft evenveel elementen als er positieve irrationale getallen en dat zijn er veel en veel meer als er natuurlijke getallen zijn (en dat is allemaal precies te maken). Dat zorgt er voor dat veel van de rationale getallen in meer dan één verzameling Sx zitten.
Maar goed, terug naar het artikel. Het hoofdresultaat zegt iets over de aard van bijna-disjuncte families deelverzamelingen van N: onder bepaalde omstandigheden is er geen maximale bijna-disjuncte familie. Als je zo’n familie hebt kun je er een oneindige deelverzameling van N bij doen zó dat de grotere familie ook bijna-disjunct is (en nog één, en nog één, …).
Wat dit nou met loterijen te maken heeft? Ik zou willen zeggen dat ik geen idee heb maar dat heb ik wel. Ik vind de vergelijking echter zó vergezocht dat ik de lezer er niet mee lastig wil vallen. En ik denk eigenlijk dat de uitleg van die vergelijking lastiger is dan die van het resultaat zelf.
Dikke en dunne verzamelingen
Gisteren hebben we gekeken naar de wiskunde achter het vermoeden van Duffin en Schaeffer. Wat daar niet goed uit de verf kwam waren de noties van `dikke’ en `dunne’ verzamelingen. Daar doen we vandaag wat aan.
Zoals gisteren en in de krant beschreven gaat het vermoeden van Duffin en Schaeffer over benaderingen van irrationale getallen met behulp van breuken. De situatie is als volgt: neem een rij (xn)n van positieve reële getallen en noem een irrationaal getal α goed benaderbaar, volgens de gegeven rij, als er oneindig veel natuurlijke getallen n bestaan met voor elk van die n een breuk t/n met noemer n bestaat zó dat |α-t/n|<xn.
De vraag is dan natuurlijk of er irrationale getallen zijn die goed te benaderen zijn. Gisteren hebben we gezien dat als x_n=n-2 alle irrationale getallen goed te benaderen zijn. Met een beroep op de gisteren ook genoemde Categoriestelling van Baire kunnen we laten zien dat er altijd heel veel goed benaderbare irrationale getallen zijn. Net als gisteren bekijken we voor elke n de intervallen (0,xn), (1/n-xn,1/n+xn) … (1-1/n-xn,1-1/n+xn), (1-xn,1). Hun vereniging noemen we An.
Neem een (klein) interval (a,b) binnen (0,1); dan geldt voor elke n met 1/n<b-a dat An en (a,b) een niet-lege doorsnede hebben (bedenk maar eens waarom dat zo is). Dit betekent dat indien we voor elke n de verzamelingen An, An+1, An+2, … verenigen tot de verzameling On we een verzameling krijgen die met elk intervalletje getallen gemeen heeft. De stelling van Baire garandeert nu dat er heel veel getallen bestaan die tot alle On behoren, en dus tot oneindig veel van de An (denk daar ook maar eens goed over na). Al die getallen zijn dus goed benaderbaar, volgens de gegeven rij.
In topologische zin is het complement van die verzameling goed benaderbare getallen nogal dunnetjes, in het Engels: meagre; de verzameling goed benaderbare getallen is dus, topologisch gesproken, bijna het hele interval (0,1) een dikke verzameling dus.
Het vermoeden van Duffin en Schaeffer ging over een andere notie van dik en dun. Laten we de verzameling goed benaderbare getallen, bij de rij (xn)n, even noteren met G(x). De nu bewezen stelling kijkt naar de (totale) lengte van de intervalletjes die we hierboven gebruikt hebben. Voor elke n is de totale lengte van An gelijk aan 2×n×xn. Als de xn-en te klein zijn zal de verzameling G(x) volgens deze notie als dun aangemerkt worden in die zin dat de kans dat een irrationaal getal goed benaderbaar is gelijk is aan 0.
De stelling van Dimitris Koukoulopoulos en James Maynard spreekt uit dat voor elke rij (xn)n de verzameling G(x) hetzij kans gelijk aan 1 heeft om geraakt te worden, hetzij kans 0; een tussenweg is er niet. Daarnaast geeft de stelling precies aan voor welke rijen kans 1 geldt en voor welke rijen kans 0.
We hebben hier dus twee soorten `dik en dun’ gezien: topologisch en kanstheoretisch. Beide noties worden in de Analyse toegepast om te laten zien dat bepaalde objecten bestaan: als je laat zien dat de verzameling van die dingen `dik’ is is die zeker niet leeg.
Voor topologen is de verzameling goed benaderbare getallen altijd `dik’; voor kansrekenaars is hij soms `dik’ en soms `dun’. Dit klinkt paradoxaal, maar is het niet: het is `gewoon’ een gevolg van de definities. En het illusteert wel treffend de titel van de column die gisteren is aangehaald: ‘De kans is nul’ is niet hetzelfde als ‘dat gaat niet gebeuren’.
Het vermoeden van Duffin en Schaeffer
Recentelijk is het Duffin-Schaeffer-vermoeden bewezen. U kunt de preprint hier lezen. In de krant is er ook aandacht aan besteed. Ik wil hier iets meer over de wiskunde achter dit vermoeden vertellen.
Het vermoeden, nu dus een stelling, zegt iets over het benaderen van irrationale getallen met behulp van rationale getallen. De vraag is in het algemeen hoe efficiëent dergelijke benaderingen kunnen zijn.
Nu zullen de meningen over wat efficiënt is uiteen lopen maar de benaderingen die we in de praktijk gebruiken, namelijk afgekapte decimale ontwikkelingen, zijn het niet echt. Als die afgekapte ontwikkelingen als breuk schrijft is die breuk vrijwel nooit te vereenvoudigen: de benadering 3.14159265358979323846264338327 van π levert een onvereenvoudigbare breuk met een grote teller en een grote noemer.
Een goede benadering is er een waar de nauwkeurigheid groot is, vergeleken met de grootte van teller en noemer. Zo kun je 22/7 een goede benadering van π noemen omdat het verschil 22/7-π kleiner is dan 1/49. Het criterium dat we hier hanteren is: p/q is een goede benadering van α als |α-p/q| kleiner is dan 1/q2. Overigens is 19/6 ook een goede benadering: 19/6-π is kleiner dan 1/36.
Een beetje spelen met een rekenmachientje laat zien dat er geen goede benaderingen van π zijn met noemers 8 of 9.
Het vermoeden van Duffin en Schaeffer, nu dus de stelling van Dimitris Koukoulopoulos en James Maynard, gaat overigens niet over individuele irrationale getallen als π of √2. Het bekijkt de zaak van de andere kant en doet uitspraken over hoeveel irrationale getallen veel goede benaderingen hebben.
Je kunt bijvoorbeeld een vaste noemer n nemen en kijken welke getallen een goede benadering met noemer n hebben. Hierbij beperken we ons tot het interval (0,1); getallen in andere intervallen krijgen we door over een geheel getal op te schuiven.
Nu is meteen duidelijk welke getallen een goede benadering met noemer n hebben: die liggen in de intervalletjes van de vorm (k/n-1/n2,k/n+1/n2), met k=1,…,n-1, en in (0,1/n2) en (1-1/n2,1).
De totale lengte van die intervallen is gelijk aan 2/n (reken maar na).
Hiermee kun je voorspellingen doen: omdat 2/10+2/11+2/12+2/13+2/14+2/15 kleiner is dan 1 zijn er getallen zonder goede benadering met noemers 10 tot en met 15.
Noem de vereniging van de intervalletjes hierboven even An. Met behulp van de Categoriestelling van Baire kun je bewijzen dat er een relatief `dikke’ deelverzameling van het interval (0,1) is waarvan elk element tot oneindig veel van de An behoort en dus oneindig veel goede benaderingen heeft.
Dit nu is de aard van de stelling van Dimitris Koukoulopoulos en James Maynard: deze geeft, bij bepaalde definities van `goede benadering’, voorwaarden onder welke de verzameling getallen met oneindig veel goede benaderingen heel `dik’ is of juist heel `dun’, waarbij `dik’ en `dun’ ondubbelzinnige definities hebben. Daarnaast geeft de stelling ook een dichotomie: `dik’ en `dun’ zijn de enige mogelijkheden. Het is nooit zo dat ongeveer de helft van de getallen oneindig veel goede benaderingen hebben; de kans is altijd gelijk aan nul (wat niet betekent dat er geen getallen zonder oneindig veel goede benaderingen zijn) of gelijk aan één.
In het krantenartikel wordt nog het volgende voorbeeld van `mooie’ benaderingen gegeven: als hierboven moet |α-p/q| kleiner zijn dan 1/q2, maar q moet zelf ook een kwadraat zijn. In dat geval is de kans op oneindig veel mooie benaderingen gelijk aan nul, maar de bovengenoemde stelling van Baire garandeert toch dat er heel veel irrationale getallen met oneindig veel goede benaderingen zijn.
Ten slotte: voor de definitie van `goed’ waar dit stuk mee begon geldt dat <emelk irrationaal getal oneindig veel goede benaderingen heeft. Dat bewijs je niet met de methoden die hier beschreven zijn, daar moet je wat dieper de getaltheorie in duiken. Zie hiervoor de Wikipediapagina’s over Benaderingsstelling van Dirichlet en over Kettingbreuken.
Recent Comments