
KP Hart
Eindexamen Wiskunde II, vwo, 1975
Nog meer jeugdsentiment: het examen wiskunde II uit 1975. Ik weet niet meer welke methoden ik op dat moment tot mijn beschikking had. Mijn uitwerkingen zijn hier zeker beinvloed door dingen die ik later geleerd heb.
Eindexamen Wiskunde I, vwo, 1975
Via de site van Henk Hofstede vond ik het examen Wiskunde I dat ik in 1975 gedaan moet hebben. Ik moet bekennen dat ik het niet meer herkende. Ik heb het nog maar eens gemaakt. Hier zijn mijn uitwerkingen.
Eindexamen wiskunde-B, vwo, 11-05-2023
De opgaven zijn te vinden op examenblad.nl; zie hier voor mijn uitwerkingen en opmerkingen.
Ik vond het een beetje wisselend. Heel flauwe, bijna voorgekauwde, opgaven met hier en daar een vraag die meer dan één stap diep gingen.
Eindexamen Wiskunde-B, vwo, 2022-07-06
De opgaven zijn te vinden op examenblad.nl. Hier zijn mijn uitwerkingen en commentaar. Ik was iets aardiger dan het tweede examen. Een paar keer moest een beetje worden doorgedacht.
Eindexamen Wiskunde-B, vwo, 2022-06-17
Ik heb het examen gemaakt en van commentaar voorzien.
De opgaven zijn te vinden op examenblad.nl. Hier zijn mijn uitwerkingen en commentaar. Ik vond het iets minder opwindend dan het eerste examen. Het grootste gedeelte van de tekst bij de-som-met-een-toepassing had niets met de opgave zelf te maken.
Eindexamen Wiskunde-B, vwo, 2022-05-20
Ik heb het eindexamen gemaakt en van commentaar voorzien.
De opgaven zijn de vinden op examenblad.nl. Hier zijn mijn uitwerkingen en commentaar. Ik vond het examen te doen. Van de twee verhalen-bij-de-opgaven vond ik die van het tekenen van letters niet zo sterk, de opgaven over de lavabommen sneden iets meer hout.
Eindexamen Wiskunde-B, havo, 2022-05-13
Ik heb het examen maar weer eens gemaakt en van commentaar voorzien.
De opgaven zijn te vinden op examenblad.nl. En hier zijn mijn uitwerkingen en commentaar. Het examen had een mix van `echte’ sommen en sommen met verhaaltjes. De sommen met verhaaltjes hadden uiteindelijk niet altijd echt veel met het onderwerp te maken.
De tafel van oneindig III: twee keer oneindig
We gaan zien dat de tafel van oneindig eigenlijk heel eenvoudig is: twee keer oneindig is oneindig, drie keer oneindig is oneindig, vier keer oneindig is oneindig, … Maar het is niet helemaal eenvoudig in te zien dat die tafel zo eenvoudig is …
Laten we beginnen met twee keer oneindig. We hebben twee zakken met oneindig veel M+M’s: een zak met blauwe en een zak met rode. Die M+M’s leggen we neer en wel zo dat we duidelijk twee keer oneindig zien:

Ik heb de rechthoek maar gekanteld, anders was het plaatje wel erg hoog en dun geworden. Nu willen we zien dat we evenveel M+M’s hebben als in één zak met oneindig veel oranje M+M’s. Dat doen we met de hagelslagmethode: de blauuwe en rode M+M’s op een rij leggen naast de oranje M+M’s op zo’n manier dat elke blauwe/rode bij één oranje M+M hoort, en elke oranje M+M naast één blauwe of rode ligt.
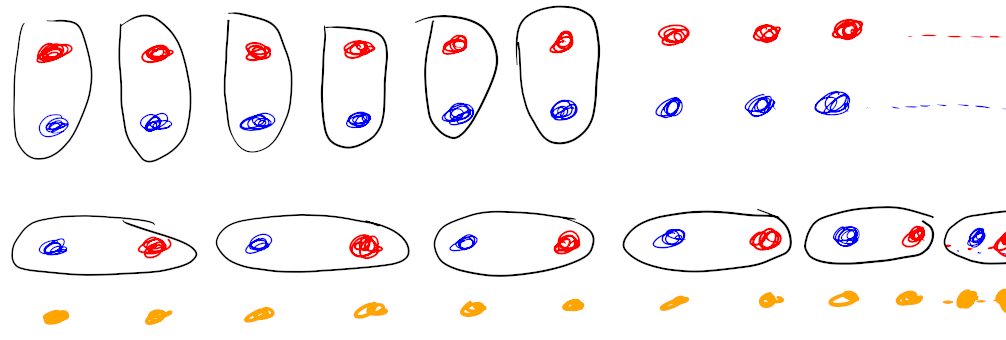
We leggen eerst de oranje M+M’s op een rij. Daarna nemen we telkens een de meest linkse blauwe en een rode M+M’s en leggen die achterelkaar, blauw eerst en dan rood, naast de eerste twee oranje M+M’s die nog geen blauwe of rode buur hebben. Omdat de M+M’s netjes op rijtjes liggen komen ze allemaal aan de beurt: elke blauwe en elke rode krijgt één oranje partner, en elke oranje krijgt één blauwe of rode partner.
In twee zakken met oneindig veel M+M’s zitten er net zoveel als in één zak. Dat klinkt gek, maar in de wereld van oneindig werken sommige dingen nou net anders dan je zou verwachten.
Laat nu zelf maar eens zien dat drie keer oneindig gelijk is aan oneindig; volg de methode voor 3×5 maar, met blauwe, rode, en groene M+M’s. En als dat lukt kun je ook wel zien waarom de tafel van oneindig iedere keer hetzelfde antwoord oplevert: vier keer oneindig is oneindig, vijf keer oneindig is oneindig, …
En oneindig keer oneindig? Oneindig veel zakken met elk oneindig veel M+M’s? Daar zitten er net zoveel in als in één zak met oneindig veel M+M’s. Maar dat zien we volgende keer wel.
De tafel van oneindig II: vermenigvuldigen
De tafel van oneindig heeft te maken met vermenigvuldigen. We eerst even kijken hoe dat ook al weer werkt.
We doen niet al te moeilijk en bekijken 2×3. Dat product kun je tekenen: een rechthoek die 2 breed is en 3 hoog.

Als we de stippen tellen zien we dat 2×3=6. Je kunt die stippen dus op een rijtje leggen:
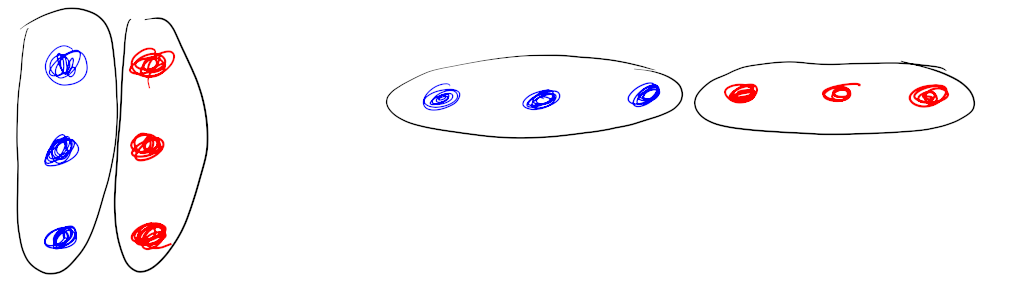
Dat kan op verschillende manieren; ook op deze manier:
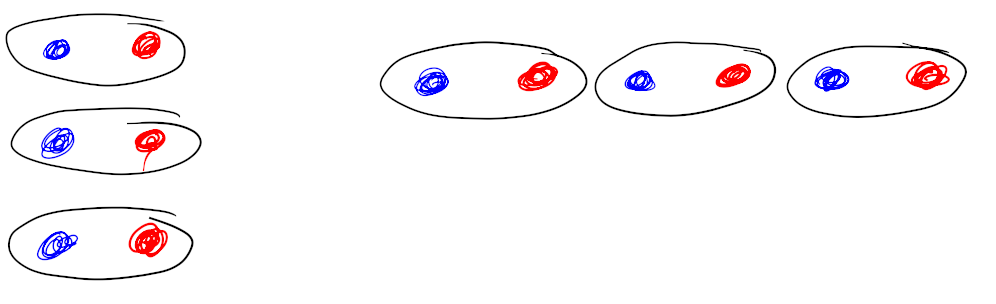
In beide gevallen krijg je een mooi rijtje van zes stippen.
Je kun dit naspelen met chocoladehagel, of M+M’s: als je 3×5 wilt bepalen maak je een rechthoek met vijf blauwe in de eerste kolom, dan vijf rode, en dan nog vijf groene. Die kun je dan mooi op één lijn leggen naast vijftien oranje M+M’s

Met dit soort plaatjes gaan we volgende keer de tafel van oneindig maken.
De tafel van oneindig I: meer, minder, of evenveel?
Op twitter werd naar de tafel van oneindig gevraagd. Die tafel is een beetje saai, er komt altijd oneindig uit. Voor we gaan zien waarom dat zo is moeten we eerst kijken hoe wiskundigen nagaan of in twee verzamelingen evenveel dingen zitten. Dat gaat niet altijd door te tellen want dat duurt soms wat lang, en als je onderweg gestoord wordt raak je misschien de tel kwijt, en moet je weer opnieuw beginnen.
Ik heb hier twee lepels chocoladehagelkorrels.

In welke lepel heb ik meer korrels? Of zitten er evenveel korrels in de lepels?

Hoe doe je dat zonder tellen? We leggen de korrels op een rijtje en vergelijken de rijtjes.
Die rijtjes maken we door telkens van elke hoop een korrel te nemen en die aan het eind van het rijtje te leggen.

Ik ben begonnen maar de korreltjes rolden telkens weg, dus ik heb het iets anders aangepakt: ik heb telkens van elk hoopje één korrel gepakt en die meteen opgegeten (ik heb het de rijtjes meteen in mijn maag gestopt) .
Aan het eind waren er rechts nog een paar korrels over, dus in de rechterlepel zaten meer korrels dan in de linker.

Je kunt dit idee voor andere gewichtige vragen gebruiken: zitten er evenveel paaseitjes in de zakjes uit de winkel? Zijn er evenveel stoelen als mensen? Zo ja, dan is de stoelendans niet echt spannend.
Dit is hoe we in de wiskunde verzamelingen vergelijken: zet ze naast elkaar op een rijtje en kijk of ze even lang worden. Dat idee gaan we volgende keer gebruiken om de tafel van oneindig op te stellen.
Recent Comments