
Posts in category taal
Spreken met haakjes
In een column van Maarten Keulemans in de Volkskrant werd aan het eind even snel aangegeven hoe groot de kans was dat er bij de Black-Live-Matter demonstratie op 2 juni iemand was die met corona besmet was. Aan het eind gebeurde iets dat mij op het verkeerde been zette.
Daar stond namelijk dit
En het protest op De Dam? Misschien had men gewoon geluk, berekende epidemioloog Frits Rosendaal (LUMC). ‘De kans om corona te hebben, was op dat moment klein, ongeveer een op tienduizend’, stelt Rosendaal. ‘Dat maakt de kans dat van de 5.000 aanwezigen er een of meer besmettelijk waren, op dat moment 39 procent: 1 min 9.999 gedeeld door 10.000, tot de macht 5.000. Vandaar dat er niks gebeurd is.’
Ik heb de zinsnede waar ik over struikelde even rood gemaakt. Het gaat mij om die komma.
Voor de komma staat dus “1 min 9.999 gedeeld door 10.000” en na de komma “tot de macht 5.000”. Die komma had voor mij de functie van haakjes, en met Mijnheer Van Dalen aan mij zijde las ik het gedeelte ervoor als
![]()
en met de komma als haakjes las ik

en daar staat gewoon 0,00015.000 en dat is 10-20.000, veel kleiner dan 0,39 dus.
Dat was niet de bedoeling. De bedoeling was dat de haakjes heel anders stonden, namelijk zo:

Dat is nog lastig in zo’n snelle zin te formuleren; als ik dit op college zou doen zou ik het natuurlijk op het bord schrijven maar soms spreek ik het uit voor ik het opschrijf. Ik zou er dit van maken: “1 min de 5000ste macht van: 9999 gedeeld door 10000”. En bij die “9999 gedeeld door 10000” zou ik de haakjes met mijn armen uitbeelden.
Morgen zullen we even naar die 5000ste macht kijken: hoe kun je snel zien dat hij groter dan een half is? En dus die kans kleiner dan een half?
Lariekoek? II
We gaan het artikel Sets and Sentences van D. Terrence Langendoen en Paul Postal opnieuw lezen. De vorige keer heb ik de inhoud beschreven; nu bekijken we die nogmaals, maar met een wiskundig oog.
Zoals vorige keer beschreven gaat het er in het artikel om te laten zien dat in een Natuurlijke Taal de mogelijke zinnen een zeer grote collectie vormen: te groot om `verzameling’ genoemd te mogen worden. We volgen de redenering stap voor stap.
De definitie van Co-ordinate compound constituent is vorige keer al schematisch weergegeven door het volgende plaatje:
De top T is hier de co-ordinate compound constituent en de andere knopen zijn de conjucten waar T uit gevormd is. Die conjuncten bestaan uit een connectief en `constituent’. Ietwat simplistisch: T ontstaat door de constituents door middel van connectieven aan elkaar te plakken.
In punt (6) van het artikel wordt gedetailleerd beschreven hoe dat plakken in zijjn werk moet gaan, of preciezer: er wordt geformuleerd wat de relatie tussen de verzameling U van constituents en de compound T moet zijn. Uit die formulering zou je een plakmethode kunnen distilleren. Van punt (6) citeer ik deelpunt (d)
if two elements of U occur as subconjuncts of conjuncts C1 and C2 of T then C1 and C2 occur in a fixed order. Where C1 and C2 are of distinct length assume the shorter precedes; where C1 and C2 are the same length, assume some arbitrary order.
Als een student zoiets opschrijft trek ik mijn rode pen: ten eerste om het gebruik van `fixed’ en `arbitrary’ vlak achter elkaar, en ten tweede om dat `arbitrary’. Dat lees ik als “doe maar wat” en daar schrijf ik dus “Hoe dan?” bij. Ik kom straks nog op dit punt terug.
Verder in punt (6) wordt T een `co-ordinate projection’ van U genoemd en U de `projection set’ van U. Inderdaad: U is door T uniek bepaald maar niet andersom; het woord `arbitrary’ lijkt daar op te duiden.
Dan volgt een alinea waarin wordt beargumenteerd dat elke verzameling U een co-ordinate projection heeft. Dit zou `straightforward’ moeten zijn, volgens de schrijvers althans. Hier zijn de stappen (de `category Q’ die ter sprake komt is een niet nader gespecificeerde abstracte categorie van zinnen):
- Neem een verzameling U en laat k de kardinaliteit van U zijn (eindig of oneindig)
- Citaat:
Clearly, from the purely formal point of view, there is a co-ordinate compound W belonging to the category Q.
Dat klinkt mooi maar het heeft geen enkele bewijskracht; geen enkele rechtvaardiging, geen indicatie waar die W vandaan zou moeten komen. - Citaat:
Since there are no size restrictions on co-ordinate compounds, W can have any number, finite (more than one) or transfinite of immediate constituents.
Dit is slechte (wiskundige) stijl: eerst lijkt W vast, dan gaat hij alsnog variëren. Een betere formulering zou zijn: “er zijn co-ordinate compounds van alle mogelijke kardinaliteiten”. Die betere formulering maakt de bewering niet automatisch waar, er is nog steeds geen concrete rechtvaardiging gegeven. - Citaat:
W can then, in particular have exactly k such constituents.
Nogmaals: die vaste W is omgevormd tot een gepaste W. Niet mooi, maar vooruit dan maar. - De deelconjuncts van de conjuncts in W vormen een verzameling V die, volgens de regels in (6), kardinaliteit k heeft. Niks mis mee.
- Citaat:
To show that W is a co-ordinate projection of U, it then in effect suffices that there exist a one-to-one mapping from U to V.
Niet dus. Hoe je definitie (6) ook wendt of keert, dit haal je er niet uit. Wil W een co-ordinate projection van U zijn dan zal de verzameling V exact gelijk aan de verzameling U moeten zijn; een bijectieve afbeelding tussen die twee is echt niet genoeg. - Citaat:
But this is trivial, since the two sets have the same number of elements.
Dit klopt, maar ik verdenk de schrijvers ervan dat ze niet doorhebben wat hier achter zit. Georg Cantor definieerde `kardinaliteit’ op een manier die eigenlijk nietszeggend is, zie de tweede post in deze serie. Hij bewees daarna dat `hebben gelijke kardinaliteit’ equivalent is met `er bestaat een bijectieve afbeelding tussen’, maar tegenwoordig is dat laatste de definitie van het eerste.
Afsluiting
In het artikel formuleren Langendoen en Postal nu een afsluitingsprincipe. Na een waarschuwing dat niet elke co-ordinate projection noodzakelijkerwijs welgevormd is komt het volgende Closure Principle for Co-ordinate Compounding:
If U is a set of constituents each belonging to the collection, Sw, of (well-formed) constituents of category Q of any natural language, then Sw contains the co-ordinate projection of U.
Hoezo “the co-ordinate projection”? Uniciteit van die projecties is nog niet aan de orde geweest en over die collectie Sw is niet (expliciet) gezegd dat elke verzameling zinnen maar op één manier tot een grotere zin samen te voegen is.
Na een opmerking over het recursieve karakter van dit principe noemen de schrijvers de categorie S van zinnen als een categorie waarop het principe van toepassing is, althans: ze beweren dat (maar geven geen bewijs).
Dat weerhoudt ze er niet van het principe twee keer uit te spreken voor S. Eerst via een bijna letterlijke herhaling, met Q vervangen door S, en dan nog een keer met behulp van een formule(!): the co-ordinate projection van een verzameling U noteren we CP(U) en dan krijgen we
(∀U)(U⊂L → CP(U)∈L)
Hierin is L de collectie van alle elementen van de categorie S van een natuurlijke taal (voor mij betekent dat L=S want L en S hebben dezelfde elementen, maar er is misschien een subtiel verschil tussen de collectie van elementen van een categorie en de categorie zelf). Merk op dat hier het onbepaalde lidwoord definitief bepaald geworden is. Zonder het expliciet uit te spreken hebben de schrijvers kennelijk besloten dat compounding maar op één manier kan; de functienotatie CP(U) kan niet anders geïnterpreteerd worden.
Maar hoe is CP(U) gedefinieerd dan? Dat wordt niet duidelijk; een illustratie met met verzamelingen van drie, vier zinnen die tot één worden samengevoegd overtuigt mij niet.
Een soort van hierarchie
Dan komt eindelijk datgene waar ik al lang op zat te wachten: The Cantorian Analogue, waarin bewezen gaat worden dat de zinnen in een natuurlijke taal geen verzameling vormen. Overigens, een definitie van `verzameling’ hebben we nog niet echt gehad.
Het bewijs gaat aanvankelijk met gebruik van een verzameling zinnen als in de vorige post, de schrijvers gebruiken {Babar is happy; I know that Babar is happy; I know that I know that Babar is happy, …}. Die verzameling noemen ze S0.
Ik kort de zinnen even af: z0 is “Babar is happy” en, gegeven zn is zn+1 de zin “I know that zn“.
Onder de aanname dat de natuurlijke taal L aan het afsluitingsprincipe voldoet omvat L ook de verzameling S1 die bestaat uit S0 en de co-ordinate projections van de deelverzamelingen van S0 met twee of meer elementen. De formulering verdient het nauwkeurig gelezen te worden.
Then L also contains a set S1, made up of all the sentences of S0 together with all and only the co-ordinate projections of every subset of S0 with at least two elemente, that is, with a set containing one co-ordinate projection for each member of the power set of S0 whose cardinality is at least 2.
Deze zin deugt niet. De delen voor en na `that is’ spreken elkaar tegen. De eerste versie van S1 bevat alle co-ordinate projections van alle deelverzamelingen van S0 — de projecties van iedere deelverzameling —; de tweede versie bevat van elke deelverzameling (precies) één projectie. Daarnaast is de eerste versie uniek bepaald door het `all and only’, daar is `the set S1‘ dus meer op zijn plaats; in het tweede deel past `a set’ wel.
Je zou het meervoud `projections’ enkelvoud kunnen maken; dat sluit wat beter aan bij de formulering van de afsluitingeigenschap, the projection zou dan telkens de functiewaarde CP(U) kunnen zijn. Maar dan gaat het ook mis: vóór het `that is’ is de keuze van projectie duidelijk vastgelegd, maar na `that is’ zit er nog potentiële willekeur in de keuze van projectie, er staat niet expliciet dat die one projection ook echt CP(U) is.
De schrijvers geven dan een voorbeeld van hoe S1 er uit zou kunnen zien (dus toch geen welbepaalde verzameling):
{z0; z1; z2; …; z0 and z1; z0 and z2; …; z0, z1, and z2 …} (voor alle duidelijkheid: de punt-komma’s scheiden de zinnen en de komma’s dienen als connectieven in de zinnen).
Dan volgt een lange alinea waarin met veel omhaal van woorden de kardinaliteit van S1 wordt bepaald. Door het `één projectie per verzameling’ is dat niet moeilijk: dat is dezelfde kardinaliteit als die van de familie van alle deelverzamelingen van S0 en omdat S0 aftelbaar oneindig is, en dus kardinaliteit ℵ0 (alef-nul) heeft is die kardinaliteit gelijk aan 2ℵ0 (2-tot-de-macht-alef-nul) en niet ℵ1, zoals Langendoen en Postal opschrijven. Ergens bij hun bestudering van de verzamelingenleer is er iets misgegaan en is de Continuümhypothese waar geworden.
Zoals wellicht verwacht wordt dit proces voortgezet. Er komt een rij verzamelingen S0, S1, S2, …, netjes recursief gedefinieerd door Sn+1=Sn∪Kn. Hierbij is Kn telkens de verzameling projecties van deelverzamelingen van Sn. In formule
Kn={x:(∃y)(y⊆Sn ∧ x is the co-ordinate projection of y)}
Hier had dus ook Kn={x:(∃y)(y⊆Sn ∧ x=CP(y))} kunnen staan.
Op deze manier komt er een hierarchie van verzamelingen zinnen tot stand; die zinnen worden steeds complexer en de verzamelingen steeds groter. De schrijvers claimen onterecht dat voor elke n het kardinaalgetal van Sn gelijk is aan ℵn. De juiste formule is een machtsverheffing met een torentje van n tweeën, met bovenaan nog een ℵ0. Dat kardinaalgetal noteren we in de verzamelingenleer als ℶn (beth-n).
Dit verhaal culmineert in wat de schrijvers The NL Vastness Theorem noemen: Natural Languages are not sets.
Het bewijs verloopt uit het ongerijmde. Neem aan dat L een verzameling is. Het proces van co-ordinate projection definieert een injectieve afbeelding van de machtsverzameling van L naar L zelf. Dat kan niet volgens een stelling van Cantor: elke verzameling heeft strikt meer deelverzamelingen dan elementen. Tegenspraak.
Er is echter een groot MAAR, en daar gaan we het nu over hebben.
Ordeningen en lengten
Het `bewijs’ in het artikel staat vol met impliciete aannamen over het gedrag van verzamelingen die een niet-wiskundige waarschijnlijk niet zo snel zullen opvallen. Er zijn twee dingen die nogal schadelijk zijn voor de redenering zoals hierboven beschreven.
Ten eerste de ordening, ik heb er bij de beschrijving van de co-ordinate projection al op gezinspeeld: daar zit, op zijn zachtst gezegd, een onvolledigheid.
Die onvolledigheid duikt op bij de overgang van S1 naar S2, en nog erger bij de stap daarna van S2 naar S3.
Bij de eerste stap, van S0 naar S1, is er niets aan de hand: we hebben onze verzameling S0 genummerd en die nummering ordent elke deelverzameling van S0, waarmee zo’n deelverzameling een natuurlijke projectie heeft, ook als deze oneindig veel elementen heeft. Dit levert natuurlijk wel zinnen zonder einde op.
Daarna, van S1 naar S2, hebben we een probleem: er zijn (overaftelbaar) veel zinnen van oneindige lengte (allemaal even lang als de verzameling der natuurlijke getallen). Daar gaat het `fixed’ en `arbitrary’ van punt (6)(d) dus wringen. Hoe orden je zo’n verzameling zinnen? De heren Langendoen en Postal spreken zich daar niet over uit.
Gelukkig kunnen we hier de lexicografische ordening gebruiken: kijk naar het eerste teken (inclusief spaties) waar de zinnen verschillen en neem een besluit op basis van de ordening van de tekens. Zie ook de post Boekenplanken voor gevorderden waar een aspect van die ordening aan de orde komt dat hier de zaak ook compliceert: er zijn heel veel verzamelingen die de eigenschap hebben dat tussen elk tweetal zinnen oneindig veel zinnen staan en die ook geen eerste zin hebben. Als we die ordening gebruiken om projecties te maken dan krijgen we dus zinnen zonder begin, zonder einde, en met voegwoorden die gaan ten minste één kant niet zien wat ze verbinden.
Het kan nog erger. We kunnen de verzameling S2 opvatten als de familie van alle deelverzamelingen van de reële rechte R. En op die familie kan geen lineaire ordening gedefinieerd worden. Het sleutelbegrip is hier `definiëren’: er is geen formule die de familie deelverzamelingen van R zó sorteert dat elk tweetal verzamelingen vergelijkbaar is. De stap van S2 naar S3 kan eigenlijk niet genomen worden.
Ten tweede is er nog het begrip lengte van een zin. Cantor heeft een hele theorie van orde-typen (`lengten’) van lineair geordende verzamelingen ontwikkeld. Wat daar vooral opvalt is dat er veel onvergelijkbare orde-typen zijn. En die kom je ook tegen bij de stap van S2 naar S3: het voorsorteren op `lengte’ gaat dus ook al niet.
Welordeningen?
“Maar, er zijn toch welordeningen?”, hoor ik degenen die wat verzamelingenleer hebben bestudeerd opwerpen. Dat klopt, en we hebben ook nog Zermelo’s Welordeningsstelling, die zegt dat elke verzameling een welordening heeft. Bij een welordening zijn de elementen zo gesorteert dat elke deelverzameling (niet-leeg) een eerste element heeft. Welordeningen zijn ook nog onderling vergelijkbaar, dus die co-ordinate projections schrijf je zo op.
Inderdaad, maar die welordeningsstelling is equivalent met het Keuzeaxioma en daarmee hoogst niet-constructief. Zoals de verzameling S2 geen definieerbare lineaire ordening heeft heeft S1 geen definieerbare welordening.
Je kunt met welordeningen werken maar dan laat je de willekeur van het Keuzeaxioma binnen en daarmee ben elke zweem van een grammatica kwijt.
Ik weet niet of je dan nog van een natuurlijke taal kunt spreken.
Korte samenvatting
We zijn hier nog niet aan het einde van het artikel Sets and Sentences gekomen. Er gebeurt wiskundig niet veel nieuws meer en het derde deel beargumenteerd dat zo ongeveer alle theoriën over natuurlijke getallen uit de tijd van schrijven niet deug(d)en. De argumenten steunen op The NL Vastness Theorem.
In het bewijs van die stelling zitten gaten. En die gaten bestaan vooral uit ontbrekende definities en aannamen.
Zo wordt nergens echt vastgelegd wat een verzameling eigenlijk is; het dichtst bij een definitie komt men in het bewijs van de Vastness Theorem: het kenmerkende van een verzameling is dat deze een kardinaliteit, een `aantal elementen’, heeft. Dat is de omgekeerde wereld en ook niet echt nodig.
Cantor definieerde eerst `Menge’ en pas daarna `Machtigkeit’; naar moderne maatstaven hebben die definities weinig inhoud maar ze stuurden de intuïtie wel de goede kant op.
De manier waarop ik het `bewijs’ van de stelling heb opgeschreven laat zien dat die aanname over kardinaliteit vermeden kan worden; we hebben alleen goede afspraken over het hebben van meer, minder en evenveel elementen nodig en dat kan zonder die aantallen te definiëren of benoemen. Net als we geen eenheid van lengte nodig hebben om uit te maken of ik langer, korter, of even lang ben als Marc van Oostendorp: zet ons naast elkaar en je weet het.
Zoals al opgemerkt zijn de centrale noties van het artikel niet goed afgesproken; de definities lijken, gezien de gegeven voorbeelden, vooral ingegeven door de eindige situatie. Bij het suggestief opschrijven van de verzameling S1 zien we ook alleen maar eindige zinnen.
Ik vermoed dat niemand de schrijvers heeft gevraagd hoe men het zich moet voorstellen: een collectie zinnen die geordend is als de rationale getallen: zonder begin, zonder eind en met tussen elk tweetal zinnen ondindig veel andere. Hoe maak je daar een goedlopende zin van?
Lariekoek? I
Dit is de vierde in een korte serie blogposts naar aanleiding van een discussie op twitter over dit stuk op Neerlandistiek.nl van Marc van Oostendorp dat zelf weer een reactie op dit artikel van Paul Postal was. In de eerste post kwalificeerde ik een opmerking uit het stuk van Postal als lariekoek. Daar gaat deze post over.
De opmerking van Postal betreft de grootte van de `collectie’ van alle boeken in een taal. Die collectie is niet alleen oneindig groot, niet alleen overaftelbaar, maar zelfs groter dan elke denkbare verzameling. Voor (een idee van) het bewijs van deze bewering verwijst Postal naar het artikel Sets and Sentences en een boek, The Vastness of Natural Languages, beide geschreven door hemzelf en D. Terrence Langendoen.
Ik heb wat met verzamelingen en wilde daarom wel eens zien waarom de collectie boeken in een Natuurlijke Taal zo groot moest zijn. Het boek heb ik niet te pakken kunnen krijgen maar deze recensie beweert dat de kern van de inhoud al in het artikel staat. laten we dat artikel dan maar eens bekijken.
Het artikel bestaat uit drie delen: een korte inleiding, een deel waarin “naar analogie met Cantors’s resultaten” wordt beargumenteerd dat de zinnen in een natuurlijke taal geen verzameling vormen, en een deel met conclusies.
Dat tweede deel begint met wat definities die het beschrijven van constructies van nieuwe `zinnen’ uit oude mogelijk moeten maken. Het hoofdingrediënt is dat van een conjunct, dat is een eenheid die bestaat uit een connectief en een deelconjuct. Die conjuncties kunnen in/tot `co-ordinate compound constituents’ samengevoegd worden. Zo’n co-ordinate compound moet wel echt `compound’ zijn en dus uit ten minste twee conjuncten gevormd worden.
Vervolgens spreken de schrijvers af hoe uit een verzameling U van constituents een co-ordinate compound constituent T gemaakt kan worden; of beter: hoe we kunnen zien dat T uit U gemaakt is. Elke conjuct in T heeft een element van U als deelconjunct, elk element van U is deelconjunct van precies één conjuct van T, en de conjuncten in T zijn geordend (daarover later meer).
In dit geval is T een `co-ordinate projection‘ van U, en U is de `projection set van T. Let op het gebruik van `een’ en `de’ in de vorige zin.
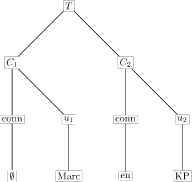
Ik kan begrijpen dat dit allemaal nogal abstract overkomt en ik moest het zelf een paar keer lezen voor ik dacht door te hebben wat er aan de hand is. Achter al die termen zitten plaatjes als het onderstaande verscholen:
De verzameling U bestaat uit de constituents `Marc’ en `KP’; uit elk element van U kunnen we een conjunct maken door er een connectief aan vast te plakken. Dat connectief kan leeg zijn, zoals bij `Marc’ omdat, bijvoorbeeld, je aan het begin van een zin geen voegwoord gebruikt en toch iets nodig hebt om je conjuct te markeren. Daar nemen we dan ∅ maar voor. In de woorden van Langendoen en Postal: C1 en C2 zijn de dochters van T, die zusters zijn elk een conjuct, bestaande uit een connectief en een deelconjuct.
De hoofdaanname, of het hoofdaxioma, is nu dat elke verzameling constituents tot een co-ordinate compound constituent gevormd kan worden. De (co-ordinate compound) constituents waar we het verder over zullen hebben zijn gewoon zinnen, en daarom zal ik ze verder ook maar zo noemen.
Om te beginnen maken we oneindig veel zinnen:
- De reële rechte is overaftelbaar
- Ik weet dat de reële rechte overaftelbaar is
- Ik weet dat ik weet dat de reële rechte overaftelbaar is
- Ik weet dat ik weet dat ik weet dat de reële rechte overaftelbaar is
- …
Niet erg opwindende zinnen maar daar gaat het niet om: er is een duidelijke procedure die voor elk natuurlijk getal n een zin Z(n) construeert. Dit is een voorbeeld van een recursieve definitie: als we een beginobject beschrijven en een recept aangeven om elk volgende object te maken dan beschouwen we de constructie als voltooid.
Voor elke deelverzameling U van deze verzameling {Z(n):n∈N} van zinnen bestaat er dus een zin waarvan de deelconjucten precies de zinnen uit U zijn. Dat geeft ons dan overaftelbaar veel zinnen.
Daarmee is het hek van de dam: we kunnen blijven doorgaan en elke deelverzameling van de nieuwe verzameling zinnen weer samensmeden tot een nieuwe zin. En weer, en weer, en weer, …
De conclusie van Langendoen en Postal is nu dat alle zinnen die we zo kunnen maken geen verzameling vormen. Hier komt de analogie met Cantor’s resultaten om de hoek kijken. Cantor bewees namelijk dat elke verzameling strikt meer deelverzamelingen heeft dan elementen. Als je dit toepast op `de verzameling van alle verzamelingen’ kom je in de knoop: de elementen van die `verzameling’ zijn precies zijn deelverzamelingen, maar dat kan niet omdat er meer deelverzamelingen dan elementen zijn. De entiteit `de verzameling van alle verzamelingen’ bestaat dus niet.
Dezelfde redenering is nu van toepassing op `de verzameling van alle zinnen in een natuurlijke taal’: elke deelverzameling bepaalt een zin en verschillende deelverzamelingen bepalen verschillende zinnen en dat druist in tegen de conclusie van Cantor: altijd strikt meer deelverzamelingen dan elementen.
Waarom Lariekoek?
Waarom denk ik dat dit lariekoek is? Dat heeft vooral te maken met de manier waarop Langendoen en Postal hun `bewijs’ presenteren. Daar is wiskundig veel op af te dingen. Maar deze post is al behoorlijk lang en ik bewaar mijn wiskundige opmerkingen, bijvoorbeeld over de bovengenoemde ordeningen daarom maar voor deel twee.
Boeken, getallen, stellingen
Vorige week ontspon zich een kleine discussie op Twitter over boeken en getallen; Marc van Oostendorp schreef Neerlandistiek.nl over een artikel van Paul Postal waarin de laatste over de aard, de ontologie, van boeken schrijft.
Boeken zijn als getallen. https://t.co/UPA1zENKqx
— Marc van Oostendorp (@fonolog) October 15, 2019
Ietwat kort door de bocht is de these van Postal dat een boek (hij gebruikte Pride and Prejudice als voorbeeld, Marc nam De Kleine Johannes als voorbeeld) als abstract object altijd al bestaan heeft, het is namelijk een rij symbolen (letters, spaties, interpunctie, …) en iemand heeft die rij een keer voor het eerst opgeschreven. Net als het getal gerepresenteerd door 7.987.923.892.274 (gezien de ene hit bij Google waarschijnlijk door Marc als eerste opgeschreven).
Voor het geval de ingebedde tweet hierboven niet goed werkt is hier een korte samenvatting van de discussie.
Mogelijke tegenwerping (Ionica Smeets): elk natuurlijk getal heeft een natuurlijke opvolger, hoe zit dat met boeken? Lijken boeken en stellingen niet meer op elkaar?
Antwoord (Marc): orden ze alfabetisch.
Ander argument (ik): dat werkt niet helemaal, als je alfabetisch wilt werken is Kleene-Brouwerorde beter, maar dan staan tussen elk tweetal boeken weer oneindig veel boeken (ik zag elke rij symbolen als een potentieel boek). Dit geldt overigens ook voor de normale Lexicografische orde van eindige rijen symbolen.
Antwoord (Marc): een boek van vijf miljard pagina’s is lang genoeg. Zou het verschil dan niet zijn dat er maar eindig veel boeken (kunnen) zijn?
Het laatste argument schuurt dan weer met de inhoud van het artikel van Postal (pagina 12): die laat willekeurig lange zinnen toe en concludeert dan dat er niet alleen oneindig veel boeken zijn maar zelfs overaftelbaar veel. Sterker nog: de boeken in een gegeven taal vormen niet eens een verzameling (volgens mij is dat laatste lariekoek maar daar hebben we het later nog wel eens over).
Is er wel verschil?
Je kunt op diverse niveau’s naar deze vraag kijken.
Representaties: rijen symbolen
Als het om opgeschreven verhalen en opgeschreven getallen gaat dan is er inderdaad geen echt verschil: beide bestaan uit rijen symbolen die hun betekenis prijsgeven als je volgens bepaalde regels (in dit geval op school aangeleerd) decodeert.
Bestonden die rijen symbolen ook al voor ze werden opgeschreven? En zo ja, hoe lang al?
Dat is een lastige vraag en waarschijnlijk voer voor lange filosofische discussies. Mijn mening: eigenlijk wel. In ieder geval sinds halverwege de negentiende eeuw (dat maakt het voor Pride and Prejudice wat onzeker): toen begon men namelijk functies als objecten te beschouwen en niet als `formules’ of `regels’. En Cantor nam, gegeven twee verzamelingen X en Y, de verzameling van alle functies van X naar Y ter hand om machtsverheffen van kardinaalgetallen te definiëren.
Als we dus voor een groot genoeg natuurlijk getal N alle functies nemen van {1,2,…,N} naar ons alfabet, aangevuld met spaties en interpunctiesymbolen, dan zit daar het verhaal van De Kleine Johannes (1884) dus ook in. In de tijd van Pride and Prejudice was de wiskunde nog niet zo ver en ik laat het aan de meer filosofisch ingestelden onder ons om te overdenken of dat boek er (ver) voor 1811 ook al was.
Het boek zelf; het getal zelf
Tot nu toe hebben we boek en getal vereenzelvigd met hun representaties. Bij een boek is dat bijna noodzakelijk. We kunnen het boek anders representeren, denk aan een lange rij nullen en enen in een e-reader, maar we hebben bij het lezen toch de oorspronkelijke rij symbolen nodig (tenzij iemand zich heeft aangeleerd de binaire code uit het hoofd te vertalen maar dat lijkt me vergezocht).
Bij een getal is dat niet zo. Neem het getal gegeven in decimale representatie als 1729 (decimale representatie) of als 6C1 (hexadecimaal) of als 11011000001 (binair). Deze representeren alledrie exact dezelfde hoeveelheid stippen, of hoop kogeltjes. En die hoop kogeltjes is de kleinste die op twee verschillende manieren in drie hoopjes verdeeld kan worden die dan elk als kubus gestapeld kunnen worden.
En Stellingen?
Ik was het in eerste instantie met Ionica eens maar nu twijfel ik. Ik vind achteraf dat stellingen dichter bij getallen liggen dan ik dacht. Een stelling heeft vele representaties maar de uiteindelijke betekenis is altijd dezelfde, net als elke representatie van een getal tot dezelfde hoeveelheid stippen, strepen, dropjes zal leiden.
Er is meer
In de tweets hadden we het ook over de mogelijkheid boeken en getallen te ordenen en het al dan niet bestaan van getallen.
Daar zal ik het in een latere post een keer over hebben.
Hon hade blivit kissnödig
Sometimes I read a book for an odd reason. In this blog a reader expressed surprise that `pee’ was being used as a noun to indicate the act of peeing, as in “She needed a pee”. This piqued my interest not because of the issue of noun versus verb but because I wanted to know what was in the Swedish original, `Solstorm’ by Åsa Larsson.
The original sentence was “Hon hade blivit kissnödig”. I found it difficult to come up with a faithful translation that is as compact as the original. Both “She needed to pee” and “She needed a pee” come close but they do not convey the exact meaning. A too-literal translation runs as follows: “She had become piss-necessary”; the `necessary’ chafes here. The term `piss-pressed’ might be better, but I could not come up with one word that describes the state of having the need to micturate.
The Swedish `att kissa’ means `to piss’ and it is an obvious candidate for a false friend between that language and English. It turns out that Google Translate has problems with the sentence too. When I had it translate “Hon hade blivit kissnödig” I got
- English: She had become kissed
- Dutch: Ze was gekust
- Norwegian: Hun ble blitt kysset
Be careful what you ask for in Sweden.
Mathsplaining
Gisteren gebruikte Aafke Romeijn in een tweet de frase mansplaining tot de macht oneindig. Ik kon nog net virtueel op mijn tong bijten maar nu moet ik toch even aan het mathsplainen.
Dat “tot de macht oneindig” klinkt wel indrukwekkend maar de kans is groot dat je er niet mee bereikt wat je wilt. Want wat betekent “tot de macht oneindig” eigenlijk? Wiskundig dan. En wat betekent “oneindig”? In dit geval zullen we het maar op het ∞ van de Analyse houden. Dan betekent “mainsplaining tot de macht oneindig” niets anders dan “de limiet van mainsplainingn voor n naar ∞”.
OK, maar dan moeten we dus eerst betekenis hechten aan “mansplaining-kwadraat”,
“mansplaining tot de derde macht”, … en vervolgens het gedrag van die machten van mansplaining bestuderen. Tsja, en dan komt het: hoe vermenigvuldig je mansplaining met zichzelf? Wiskundig betekent het woord niets maar we kunnen wat vermenigvuldigbare zaken langslopen.
We kunnen getallen vermenigvuldigen, en dus ook machtsverheffen. Maar dan komt het: is mansplaining negatief? Voor velen wel, denk ik. Jammer dan, maar dan is het kwadraat positief, de derde macht negatief, de vierde macht positief, … dan kun je het schudden: de limiet bestaat niet. Tenzij, …, je vindt dat mansplaining eigenlijk wel zielig is en weinig waarde heeft, zeg absolute waarde kleiner dan 1. Dan convergeren die machten naar 0 en dan is mansplaining tot de macht oneindig dus gelijk aan 0. Ik weet niet of dat Aafke Romeijn voor ogen stond.
Mansplaining is natuurlijk irreëel en irrationaal; dat lijkt wiskundig niet goed te gaan maar je kunt het interpreteren als “een complex getal met irrationaal argument”. Wiskundigen zien hier meteen een woordspeling: het woord `argument’ heeft in de wereld van de complexe getallen zijn geheel eigen betekenis. Dan leidt machtsverheffen tot een duizeligmakend ronddraaien; het hangt van de absolute waarde af of dit naar 0 convergeert, of naar ∞, of zonder limiet de eenheidscirkel blijft rondlopen. (Om andere mathsplainers de wind uit de zeilen te nemen: dat argument is een irrationaal veelvoud van π.)
Een mansplainer projecteert zijn eigen meningen en gedachten op hetgeen hij aan het mansplainen is. Dat leidt tot een wat merkwaardige situatie: wiskundig is het kwadraat van een projectie de projectie zelf. En dus is elke macht van mansplaining gelijk aan mansplaining zelf, met als conclusie dat mansplaining tot de macht oneindig gewoon mansplaining is. Eigenlijk wel een mooie conclusie: mansplaining is al zo erge flauwekul dat het zijn eigen oneindige macht is.
Wat is een verzameling? II
We zetten de zoektocht naar het begrip `verzameling’ voort.
In de vorige blogpost hebben we de definities die Bolzano en Cantor van `verzameling’ gaven geciteerd. Die kwamen eigenlijk neer op “een verzameling is een verzameling”. Nu is het nogal lastig om een definitie van verzameling in woorden op te schrijven zonder te vervallen in synomiemen maar het kan wel.
Rond de eeuwisseling (die van 1900) begon men ernstig over de aard van definities na te denken. De eerste stap was het vastleggen van de taal waarin die definities vastgelegd zouden worden. En met `taal’ bedoelde men niet zoiets als Grieks, Latijn, of Swahili maar een meer formele constructie. Deze gaat uit van een beperkt aantal symbolen. Sommige zijn algemeen, zoals ∧ (en), ∨ (of), ¬ (niet), ∀ (voor alle) ∃ (er is) enzovoort; en sommige zijn specifiek voor het onderhavige onderdeel van de wiskunde, in de verzamelingenleer kunnen we toe met ∈ (is element van) en = (is gelijk aan).
In deze taal kunnen we vrijwel alles beschrijven wat we willen. De taal is sterk genoeg om dingen als
- “x is een priemgetal”
- “x is een reëel getal”
- “x is een rechte lijn in het vlak”
en nog veel meer uit te drukken. Op deze manier kunnen we afspreken dat we iets alleen een verzameling noemen als het bestaat uit x-en met een eigenschap die in onze taal is uit te drukken. Dus
{x : x is een priemgetal}
is een verzameling (waarbij “x is een priemgetal” in de taal is geformuleerd). Dit komt vrij dicht in de buurt van Cantor’s definitie van verzameling: de accolades {} representeren de `Zusammenfassung zu einen Ganzen’, en we hebben `Annschauung’ en `Denken’ vervangen door `beschrijfbaar in de taal’.
De lege verzameling ∅ is uit te drukken door {x : x≠x} en telt dus mee als verzameling. Andere dingen leken iets dubieuzer, zoals {x : x=x}, de verzameling, V, van alle verzamelingen(?). Die gaf aanleiding tot een paradoxale toetand: Cantor had bewezen dat elke verzameling strikt minder elementen dan deelverzamelingen heeft (zie deze en de daarop volgende post voor de betekenis van meer en minder), maar voor deze V geldt dat niet, want elke deelverzameling is automatisch ook een element.
De oplossing, van Cantor, was onderscheid te maken tussen gewone en `oneigenlijke’ verzamelingen. En V was dus oneigenlijk; te groot om als gewone verzameling mee te tellen. Dat dit niet de schoonheidsprijs verdient lijkt me duidelijk want wie bepaald wat gewoon en oneigenlijk is?
Het kon nog erger: Bertrand Russell schreef de volgende verzameling, R, op: {x : x∉x}. Deze R leidt tot een wel heel eenvoudige paradox/tegenspraak, namelijk “$R∈R dan en slechts dan als R∉R”. Hier zijn geen diepe stellingen voor nodig; de afspraak hierboven was vanaf het begin al dubieus.
De uiteindelijke oplossing kwam van Ernst Zermelo. Deze formuleerde een een lijst axioma’s (spelregels) die we in acht moeten nemen als we met verzamelingen omgaan. Deze geven vooral aan hoe nieuwe verzamelingen uit oude gevormd kunnen/mogen worden. Die regels zijn redelijk natuurlijk; zo mogen we, gegeven twee verzamelingen x en y de verzameling {x,y} vormen.
Een van de belangrijkste regels is het Afscheidingsaxioma; dit zwakt onze eerste beschrijving wat af. Als x een gegeven verzameling is en φ is een formule in onze taal dat is {y:y∈x ∧ φ} weer een verzameling. Het verschil is dus dat we al een verzameling moeten hebben en daarbinnen elementen met een bepaalde eigenschap bijeen nemen.
Wat voor veel mensen in begin nog even wennen is is dat elk individu waar uitspraken over worden gedaan een verzameling is. Dus de elementen van verzamelingen zijn zelf ook weer verzamelingen enzovoort. Dat impliceert ook dat dingen als natuurlijke en reële getallen beschrijvingen krijgen die niet lijken op wat we gewend zijn maar dat went uiteindelijk wel.
Maar goed, dit leidt dan tot de volgnde definitie van verzameling: iets waarvan het bestaan uitgaande van de axioma’s te bewijzen is.
En wat dan allemaal uitgaande van die axioma’s mogelijk is kunt u in elk boek over Verzamelingenleer lezen en ook in het dictaat van de cursus Verzamelingenleer die ik zelf gegeven heb.
Voegwoorden en rekenen
“Taal is geen Wiskunde” schreef @onzetaal als reactie op de vorige post. Inderdaad.
In 2002 stond in het tijdschrift Onze Taal een artikel Alle Aaanwezigen Behalve De Kinderen waarin de werking van voegwoorden gerelateerd werd aan, vooral, optellen en aftrekken.
En, helaas, na een bladzijde voorbeelden gaat het meteen mis:
De betekenis van en is gemakkelijk: het komt overeen met de optelling van twee aantallen. In de wiskundige verzamelingenleer worden aantallen als verzamelingen voorgesteld. De betekenis van `Jan is bakker en visser’ wordt in verzamelingstheoretische termen opgevat als `Jan behoort zowel tot de verzameling bakkers als tot de verzameling vissers.’
De betekenis van en is een stuk ingewikkelder dan optellen en dat laat het geciteerde voorbeeld meteen zien: door te zeggen `Jan is bakker en visser’ verwijst men inderdaad naar de doorsnede van twee verzamelingen: Jan∊Bakkers∩Vissers. Echter `Willen alle bakkers en vissers naar voren komen’ verwijst naar een vereniging: Bakkers∪Vissers. En beide mogelijkheden komen niet overeen met optellen: in het eerste geval laten we niet-vissers weg uit de verzameling bakkers en in het tweede geval is het totale aantal mensen niet noodzakelijk de som van de aantallen bakkers en vissers want onze Jan wordt dan dubbel geteld.
Later wordt aan of ook een rekenkundige kant toegedicht. Die lijkt ook verdacht veel op optellen `Jan is bakker of visser’ verwijst (weer) naar de vereniging van de verzamelingen bakkers en vissers. “Jan behoort tot de verzameling die het resultaat is van de samenvoeging van de bakkers en de vissers. Daar moet je nog de doorsnede van aftrekken, omdat Jan niet tegelijk bakker en visser zou kunnen zijn”. Dat is nou jammer, want de tweede helft van de zin is nogal ongelukkig.
Als het er om gaat de bakkers en vissers bijeen te nemen dan is weglaten van de doorsnede niet nodig: iemand mag best bakker en visser tegelijk zijn. Als het om het totale aantal mensen gaat moet je, als boven, het anatal mensen in de doorsnede aftrekken van de som van de twee aantallen om dubbeltellen te voorkomen.
De tweede helft is ongelukkig omdat hij niets uitlegt: door het `zou kunnen zijn’ laat hij in het midden of Jan twee beroepen uitoefent, of niet en maakt hij het `omdat’ niet waar.
Ik proefde daar een beetje het verschil tussen het exclusieve of en het inclusieve of maar het kwam niet geheel uit de verf. In de omgangstaal is of veelal exclusief: een koekje of een snoepje, maar niet allebei. In de wiskunde gebruiken we het inclusieve of, een beetje uit gemakzucht maar vooral omdat het in de Logica allemaal een stuk mooier werkt.
Met de tweedeling aan het eind kan ik het wel eens zijn: er zijn twee soorten voegwoorden, die in de ene groep gedragen zich als binaire operaties (denk aan +, ∪ ∩, …) en die in de andere als binaire relaties (≤, =, ≥, ⊆, …). En daar was het in het artikel om te doen: proberen een vinger te krijgen achter het verschijnsel dat je sommige voegwoorden `binnen/buiten de haakjes kunt halen’. De zinnen `Jan is bakker en Jan is visser’ en `Jan is bakker en visser’ betekenen hetzelfde en zijn syntactisch correct. Maar van `Ik ga naar buiten omdat ik wil hardlopen’ kun je niet `Ik ga naar buiten omdat wil hardlopen’ maken; `omdat’ is hier een binaire relatie en die kun je ook in de wiskunde niet buiten de haakjes halen: 5+a=5+b is niet hetzelfde als 5=a+b.
Ten slotte
Om het werken met voegwoorden met rekenen te vergelijken ligt voor de hand maar is niet de juiste keuze. Beter is het naar de Boolese Algebra te kijken (spreek uit: Boelse Algebra). Deze is voortgekomen uit het werk An Investigation into the Laws of Thought van de Ierse wiskundige George Boole. Daarin wordt gerekend met ∧ (en) en ∨ (of), volgens regels die een beetje op die van het gewone rekenen lijken maar ook niet meer dan een beetje.
Veel van wat in het artikel wordt besproken kan hiermee geanalyseerd worden. De ervaring leert dat de studenten met dat rekenen niet zoveel moeite hebben. Het kost ze (en niet alleen de studenten) veel meer moeite normale zinnen correct naar dit formalisme te vertalen.
Recent Comments