
Posts in category Uncategorized
Perforaties en definities
Op Facebook, in de groep Leraar Wiskunde, kwam een vraag langs die een mooi excuus oplevert voor een wat algemenere beschouwing over definities.
Perforaties
De vraag ging over perforaties in grafieken van functies. Een perforatie is een gat in de grafiek dat gedicht kan worden op zo’n manier dat de functie continu wordt in dat punt. Dit was de informele definitie.
De formele definitie werd in de vraag uit een leerboek geciteerd: de grafiek van f heeft een perforatie in (a,b) als f(a) niet bestaat en als de limiet van f(x) voor x nadert tot a gelijk is aan b. Verder kwam een voorbeeld uit het boek ter sprake waarin duidelijk aan deze definitie werd voldaan. Einde verhaal zou je zeggen. Ware het niet dat de vraagsteller vond dat er `gevoelsmatig’ meer aan de hand zou moeten zijn. Ik heb het voorbeeld nagetekend.

De functie is links en rechts van 2 door verschillende formules gegeven en f(2) is expliciet niet gedefinieerd. Aan de eerste eis is voldaan: f(2) bestaat niet. Verder zijn linker- en rechterlimiet snel bepaald, ze zijn gelijk aan 2. Daar is de tweede eis: de limiet is gelijk aan 2. We hebben een perforatie in (2,2). De vraagsteller vond (`gevoelsmatig’) dat eigenlijk de linker- en rechterlimieten van de afgeleide ook aan elkaar gelijk zouden moeten zijn.
Definities
De discussie onder de vraag ging eigenlijk meer over wat een perforatie zou moeten zijn in plaats van wat het eigenlijk is. Wat aan het geciteerde boek valt te prijzen is dat er een definitie gegeven is. En die definitie is een minimale exacte beschrijving van: “er zijn een gat in de grafiek dat bij opvulling de functie in dat punt continu maakt”. De eis dat f(a) niet bestaat is de vertaling van “er is een gat” en de eis dat de limiet bestaat vertaalt “bij opvulling wordt de functie continu in dat punt”.
In een paar andere bronnen vond ik niet meer dan een definitie door voorbeeld: “als wat hier gebeurt elders ook gebeurt spreken we van een perforatie”.
Het voordeel van de definitie uit het boek is dat deze kort en krachtig is en daardoor ook zonder omhaal te verifiëren. In de discussie op facebook kwamen wel bezwaren naar voren maar die waren denk ik ingegeven door non-definities als die uit de andere bronnen. In de voorbeelden was vaak meer aan de hand: de functies was bijvoorbeeld een rationale functie waarin de kandidaat-perforaties onder de nulpunten van de noemer gezocht werden en door gemenschappelijke factoren in teller en noemer geïdentificeerd konden worden. En `eigenlijk’ zouden alle perforaties er zo uit moeten zien.
Maar de kracht van de meeste wiskundige definities is juist het kernachtige ervan. Bolzano had een definitie van continuïteit die heel dicht bij de huidige kwam en die is met ε en δ en al afkomstig van Weierstrass. Die definitie bleek echt het wezen van de continuïteit te vangen: hij geeft ons de Tussenwaardestelling (van Bolzano) en de het bestaan van extremen op gesloten intervallen (Weierstrass).
De definitie laat ook schijnbare uitwassen toe met als de mooiste voorbeelden (voor mij) de nergens differentieerbare functies van Weierstrass en Peano’s vlakvullende kromme. Hermite moest er niets van hebben, zoals hij aan Stieltjes schreef: “Je me détourne avec effroi et horreur de cette plaie lamentable des fonctions continues qui n’ont point de dérivées …”.
De moraal: de taak van een definitie is de kern van de zaak samen te vatten. Dat doet de definitie van perforatie prima, en met niet meer dan echt nodig is.
Alternatieve functies?
Een vraag op de Wisfaq:
De exponentiële functie exp(ax), waarbij a een constante is, is voor alle x-waarden positief. Dat geldt voor zowel negatieve als voor postieve x-waarden. Als deze functie echter voorkomt in andere functies wordt het vinden van een uitdrukking bij integreren dikwijls onmogelijk.
Bestaat er een alternatief voor deze functie, waarbij als de functie voorkomt in een andere functie integreren wel makkelijk gaat? In het alternatief moet dus ook gelden, dat de functie voor alle x-waarden positief is en ook gedefinieerd is voor alle x-waarden.
Ik vind deze vraag tegelijkertijd aardig en onzinnig.
Aardig
Hoezo “aardig”? Ik begrijp de frustratie als een uitdrukking weer eens niet in gesloten vorm te primitiveren blijkt en ik kan me voorstellen dat iemand zich afvraagt of we daar niets aan kunnen doen. Maar, helaas, die frustratie gaat voorbij aan de werkelijkheid en daarom …
Onzinnig
Het woord “onzinnig” klinkt wat scherp maar ik kon niet iets beters verzinnen. Primitiveren in gesloten vorm heeft zijn charmes en zijn nut; het is altijd leuk iets in een niet al te lelijke formule te vangen en die expliciete primitieven kunnen tot verder inzicht leiden.
Echter, en dat komt misschien als een verassing, eigenlijk is dat primitiveren in gesloten vorm min of meer een illusie.
Iemand die alleen kan optellen, aftrekken, vermenigvuldigen, en delen ken alleen de zogeheten rationale functies: quotiënten van polynomen. Die persoon zal niet in staat zijn de functie 1/x te primitiveren. Maar die primitieve is belangrijk bij het bepalen van oppervlakten van gebieden begrensd door hyperbolen. De oplossing: geef die primitieve een naam en probeer zoveel mogelijk eigenschappen van die functie te vinden om ermee te kunnen werken. Die functie heet nu de natuurlijke logaritme en is onderhand een `bekende’ functie geworden. Net zoals de inverse van die natuurlijke logaritme en dat is de exponentiële functie. Die functies zijn zo grondig bestudeerd dat ze net als optellen, aftrekken, vermenigvuldigen, en delen tot ons standaardgereedschap zijn gaan behoren, net als onderhand ook allerhande wortel- en de goniometrische functies. Bedenk hierbij dat zelfs √x een impliciet bepaalde functie is: de inverse van de kwadraatfunctie.
In dit verband zou je naar analogie van de wisfaqvraag kunnen verzuchten: “Kunnen we dat delen niet door wat anders vervangen want we kunnen veel breuken niet primitiveren.”
In de mathematische fysica, kansrekening, en vele andere toepassingsgebieden van de Analyse komen die vervelende niet-te-primitiveren functies heel vaak voor en men heeft daar gedaan wat dus eerder met de logaritme en exponentiële functie is gebeurd: de primitieven hebben namen gekregen.
Bijvoorbeeld exp(-x2), bekend van de normale kansverdeling; de primitieve heeft een naam gekregen: de Error function. En onder de gebruikers is die Errorfunctie net zo vertrouwd als de `elementaire’ functies van de Analyse. Er zijn nog veel meer van dit soort functies benoemd, zie bijvoorbeeld de Wikipediapagina over Special Functions.
Daarnaast, en dat is eigenlijk de hoofdreden voor het predicaat “onzinnig”, de exponentiële functies zijn niet voor niets zo alomtegenwoordig; zo ongeveer elke poging processen in de echte wereld te beschrijven leidt tot deze functies of functies waar deze in verstopt zit. Je kunt hem wel weg willen wensen maar de werkelijkheid is te weerbarstig.
Wat zou het nut van die alternatieve functies zijn?
Hoeveel reële getallen?
Een paar maanden geleden stond er een artikel in Quanta magazine over het aantal reële getallen, een vraag die verzameltheoreten al bijna 150 jaar bezig houdt.
Het begin van het artikel beschrijft in de ietwat hijgerige stijl van Quanta de vermeende implicaties van een recent resultaat van David Asperó en Ralf Schindler: een implicatie tussen twee niet-triviale verzameltheoretische principes.
Die implicaties betreffen Cantor’s ContinuumHypothese. De oorspronkelijke formulering had te maken met het indelen van de oneindige deelverzamelingen van de reële rechte R in klassen door middel van bijecties (een-op-eencorrespondenties). Cantor dacht/vermoedde dat er voor een oneindige deelverzameling, X, van R maar twee mogelijkheden ware: in bijectie met R zelf of in bijectie met de verzameling N der natuurlijke getallen.
Later kwam er een nieuwe versie van dat vermoeden. Cantor had namelijk een meetlat van kardinaalgetallen ontwikkeld om aan oneindige verzamelingen ook een “aantal elementen” toe te kunnen kennen. Die getallen werden genoteerd als ℵα, waarbij α een andere meetlat doorloopt. Cantor’s vermoeden kwam neer op de bewering dat zijn toekenning van “aantal elementen” voor R het resultaat ℵ1 zou geven. Wat we nu weten is dat de huidige axioma’s van de verzamelingenleer niet sterk genoeg zijn om te bewijzen dat het “aantal elementen” van R inderdaad gelijk is aan ℵ1 (het kleinst mogelijke), en ook niet sterk genoeg om te bewijzen dat dat niet zo is.
Door de jaren heen hebben verzameltheoreten geprobeerd nieuwe axioma’s te formuleren die “natuurlijk” zijn en die een definitief antwoord geven op de vraag naar het “aantal elementen” van R. Het resultaat van Asperó en Schindler verbindt twee van dergelijke axioma’s. Het ene heet Martin’s Maximum++ en het andere gaat onder de weinig informatieve naam (*). Beide impliceren dat het “aantal elementen” van R gelijk is aan ℵ2. Dat is n kardinaalgetal hoger dan Cantor hoopte en zegt dat er voor de oneindige deelverzamelingen van R nog een derde mogelijkheid is naast de twee die hierboven genoemd zijn.
Wat Asperó en Schindler hebben laten zien is dat (*) een gevolg is van Martin’s Maximum++. Wie het artikel leest zal zien dat de formuleringen van de twee principes en het bewijs van de implicatie verre van eenvoudig zijn. Dat bewijs mag met een gerust hart een mijlpaal genoemd worden.
Maar brengt het ons dichter bij de oplossing van Cantor’s probleem? Dat is nog maar de vraag, zoals gezegd: de principes zijn niet eenvoudig en hun consistentie met de gebruikelijke axioma’s vergt nogal wat machinerie. Daar hebben we het nog niet over gehad: het is mooi dat die principes een oplossing van Cantor’s probleem opleveren maar dat helpt niet als hun negaties uit de gebruikelijke axioma’s af te leiden zouden zijn. Dat is gelukkig niet zo maar de moeite die het kost dat vast te stellen laat ze wat minder natuurlijk klinken.
Aan het eind van het stuk in Quanta wordt een even natuurlijk (of even onnatuurlijk zo u wilt) principe besproken dat Cantor’s probleem nu juist oplost zoals Cantor dat wilde.
Wat is nu de conclusie? Er is in het bouwwerk van implicaties tussen allerlei verzameltheoretische principes een belangrijke pijl toegevoegd. Maar die nieuwe pijl brengt ons (in tegenstelling tot de titel van het artikel) niet echt dichterbij een oplossing van Cantor’s probleem. De nieuwe pijl maakt de principes die hij verbindt niet automatisch meer natuurlijk dan andere potentiële axioma’s.
Eindexamen wiskunde B vwo 2021-07-07
Eergisteren was de derde gelegenheid voor wiskunde B (vwo). De opgaven staan op examenblad.nl. Ik heb de opgaven gemaakt en eigenlijk weinig commentaar, ze leken mij goed te doen. Zelfs de `contextopgave’ was redelijk, zonder al te veel tekst.
Eindexamen wiskunde B vwo 2021-06-18
Afgelopen vrijdag was de tweede zitting wiskunde B voor het vwo. De opgaven zijn hier te vinden. Ik heb de opgaven gemaakt en van commentaar voorzien; er viel me eigenlijk niet veel op.
Eindexamens wiskunde A en B, havo, 2021-05-26
Gisteren waren de eindexamens wiskunde A en wiskunde B van de havo (opgaven onder de links). Ik heb de opgaven bekeken en ik wil hier wat commentaar leveren.
Wiskunde A: twaalf bladzijden tekst met 24 vragen. In voorgaande jaren heb ik het examen wel eens gemaakt en de individuele vragen van commentaar voorzien maar daar heb ik nu geen tijd genoeg voor. En ik moet zeggen: al lezende verging mij de lust de sommen te maken; heel veel tekst met vragen die vaak neerkomen op, na enige reflectie, indrukken van de juiste knoppen op een rekenmachine. Er waren uitzonderingen: vraag 16 vraagt welk plaatje van een kansverdeling hoort bij “hoog gemiddelde, lage mediaan”; vraag 22 wil een rechtvaardiging zien van coefficienten in een, op het eerste gezicht, nogal rare vergelijking .
Op de eerste bladzijde moest ik even slikken: daar werd gesproken over “tweemaal zo dichtbij” en “hoeveel keer zo dichtbij” bij een verhaal over het testen van het gezichtsvermogen. Bij mijn weten is ‘dichbijheid’ geen SI-eenheid en ik vind het verdubbelen van dichtbijheid nogal dubbelzinnig. Op dit blog heb ik het ook al eens over ‘twee keer zo langzaam‘ gehad, wat hetzelfde zou moeten betekenen als ‘de halft langzamer’.
Wiskunde B: twaalf bladzijden tekst met 17 vragen (niet alle bladzijden waren geheel gevuld). Een mix van ‘echte’ wiskundevragen en wat stukken met meer tekst.
De ‘echte’ vragen gingen over functies, cirkels en lijnen, sinusoiden, … Het zag er, voor mij, niet moeilijk uit. Een enkele vraag was wel er makkelijk, vraag 7 was zo voorgekauwd dat alleen nog u3=64 opgelost moest worden.
Er waren twee vragen met tekst: een paginalang verhaal over roeimachines leidde tot twee aardige vragen over driehoeken, en aan het eind twee vragen over hardlooptijden waar de grootste klus leek te zijn het opstellen van de juiste vergelijkingen.
Eindexamen wiskunde A vwo 2021-05-17
Ik heb naast het examen wiskunde B nu ook het examen Wiskunde A gemaakt en van commentaar voorzien.
De opgaven staan op examenblad.nl en mijn uitwerkingen staan op deze plek.
In mijn uitwerkingen staan opmerkingen over de individuele opgaven. Ik wil het hier nog even over het examen als geheel hebben. Er was ontzettend veel tekst en veel van die tekst deed er niet toe. Een extreem voorbeeld was de laatste opgave: twee a4-tjes tekst met aan het eind niet veel meer dan een rekensom. Ik loop het examen even deel voor deel door.
Linkshandigheid en ronde getallen
Drie pagina’s met vijf vragen geïnspireerd(?) door een onderzoek uit 2013 dat zou hebben aangetoond/bevestigd dat linkshandige mensen vaker ronde getallen zouden noemen bij vragen naar aantallen. De rondheid van getallen zou volgens de formule van Sigurd bepaald zijn.
Ik dacht dat dit uit de duim gezogen was maar het onderzoek heeft echt plaatsgevonden; lees erover in PLOS One. En Bengt Sigurd was een Zweedse taalkundige die in 1988 een artikel over Round Numbers publiceerde.
De extra tekst wekt hoge verwachtingen maar de uiteindelijke opgaven zijn veelal niet echt moeilijk.
Draaiend huis
Na een lege pagina gaan we naar Tilburg, het draaiende huis van John Körmeling. Dat huis is aanleiding tot een vier vragen over roterende objecten en een sinusfunctie.
Mathematical Bridge
Een brug in Cambridge geeft ons drie vragen over een cirkel en een raaklijn daar aan.
The International
Goed voor vijf vragen. Het gaat over prijzengelden en teamsamenstellingen by on-line gaming: E-sports. Drieënhalve pagina tekst voor vijf korte vragen. Wel een mix: exponentiële groei, wat combinatoriek, en functieonderzoek. Maar de wiskundige inhoud had met veel minder omhaal gevraagd kunnen worden. Op twitter werd al een poging gedaan.
Hier een poging. De inleiding van de vraag met onderaan mijn iets kortere versie ervan. pic.twitter.com/czw6hTod8g
— Casper Hulshof 👻 (@CasperHuls) May 19, 2021
Huurprijzen in New York
Drie vragen: twee over exponentiële groei en een grafiek-leesvraag.
Inkomensongelijkheid
Twee volle bladzijden met aan het eind één rekensom. Ik had eerst niet door dat de vraag ging over het verschil van twee soorten inkomensverschillen. Er was één symbool, S, voor een inkomensverschil en de vraag had het over “het verschil tussen de S bij het secundaire inkomen en die bij het primair inkomen”.
En toch …
Het is makkelijk grappen maken (of klagen) over dit soort examens met lappen tekst waar de sommen soms aan de haren bijgesleept lijken. Maar het is een belangrijke vaardigheid: uit een lap tekst de juiste dingen halen om verder mee te werken. De vraag is wel of je dat op deze manier op een moment met allerlei extra spanning moet gaan zitten toetsen.
wiskunde vmbo GL en TL 2021
Op twitter werd ik gevraagd ook eens naar het examen uit de titel te kijken. Dat heb ik gedaan.
De opgaven zijn weer op examenblad.nl te vinden. Mijn uitwerkingen en commentaar staan op deze plek.
Ik heb geen ervaring met wiskunde op het vmbo, dus ik zag eigenlijk voor het eerst zo’n examen. Wat getest werd was een mix van elementaire rekenvaardigheden (soms was optellen/aftrekken/vermenigvuldigen/delen genoeg) en wat moeilijker zaken zoals goniometrie en meetkunde, en werken met exponentiele zaken. Allemaal dingen waarvan je zou willen dat iedereen wat kaas van gegeten heeft.
Waar ik niet helemaal achter kwam is hoe de sommen gedaan zouden moeten worden; het correctievoorschrift was daarvoor te summier. Mijn oplossingen zijn waarschijnlijk niet standaard.
Eindexamen wiskunde B vwo 2021-5-17
Het eindexamen wiskunde B (vwo) werd gisteren afgenomen. De opgaven te vinden op examenblad.nl
Ik heb het examen gemaakt en van opmerkingen voorzien de uitwerking is te vinden op mijn website. Het leek mij goed te doen.
Lariekoek? I
Dit is de vierde in een korte serie blogposts naar aanleiding van een discussie op twitter over dit stuk op Neerlandistiek.nl van Marc van Oostendorp dat zelf weer een reactie op dit artikel van Paul Postal was. In de eerste post kwalificeerde ik een opmerking uit het stuk van Postal als lariekoek. Daar gaat deze post over.
De opmerking van Postal betreft de grootte van de `collectie’ van alle boeken in een taal. Die collectie is niet alleen oneindig groot, niet alleen overaftelbaar, maar zelfs groter dan elke denkbare verzameling. Voor (een idee van) het bewijs van deze bewering verwijst Postal naar het artikel Sets and Sentences en een boek, The Vastness of Natural Languages, beide geschreven door hemzelf en D. Terrence Langendoen.
Ik heb wat met verzamelingen en wilde daarom wel eens zien waarom de collectie boeken in een Natuurlijke Taal zo groot moest zijn. Het boek heb ik niet te pakken kunnen krijgen maar deze recensie beweert dat de kern van de inhoud al in het artikel staat. laten we dat artikel dan maar eens bekijken.
Het artikel bestaat uit drie delen: een korte inleiding, een deel waarin “naar analogie met Cantors’s resultaten” wordt beargumenteerd dat de zinnen in een natuurlijke taal geen verzameling vormen, en een deel met conclusies.
Dat tweede deel begint met wat definities die het beschrijven van constructies van nieuwe `zinnen’ uit oude mogelijk moeten maken. Het hoofdingrediënt is dat van een conjunct, dat is een eenheid die bestaat uit een connectief en een deelconjuct. Die conjuncties kunnen in/tot `co-ordinate compound constituents’ samengevoegd worden. Zo’n co-ordinate compound moet wel echt `compound’ zijn en dus uit ten minste twee conjuncten gevormd worden.
Vervolgens spreken de schrijvers af hoe uit een verzameling U van constituents een co-ordinate compound constituent T gemaakt kan worden; of beter: hoe we kunnen zien dat T uit U gemaakt is. Elke conjuct in T heeft een element van U als deelconjunct, elk element van U is deelconjunct van precies één conjuct van T, en de conjuncten in T zijn geordend (daarover later meer).
In dit geval is T een `co-ordinate projection‘ van U, en U is de `projection set van T. Let op het gebruik van `een’ en `de’ in de vorige zin.
Ik kan begrijpen dat dit allemaal nogal abstract overkomt en ik moest het zelf een paar keer lezen voor ik dacht door te hebben wat er aan de hand is. Achter al die termen zitten plaatjes als het onderstaande verscholen:
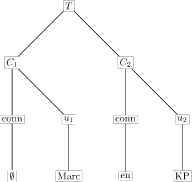
De verzameling U bestaat uit de constituents `Marc’ en `KP’; uit elk element van U kunnen we een conjunct maken door er een connectief aan vast te plakken. Dat connectief kan leeg zijn, zoals bij `Marc’ omdat, bijvoorbeeld, je aan het begin van een zin geen voegwoord gebruikt en toch iets nodig hebt om je conjuct te markeren. Daar nemen we dan ∅ maar voor. In de woorden van Langendoen en Postal: C1 en C2 zijn de dochters van T, die zusters zijn elk een conjuct, bestaande uit een connectief en een deelconjuct.
De hoofdaanname, of het hoofdaxioma, is nu dat elke verzameling constituents tot een co-ordinate compound constituent gevormd kan worden. De (co-ordinate compound) constituents waar we het verder over zullen hebben zijn gewoon zinnen, en daarom zal ik ze verder ook maar zo noemen.
Om te beginnen maken we oneindig veel zinnen:
- De reële rechte is overaftelbaar
- Ik weet dat de reële rechte overaftelbaar is
- Ik weet dat ik weet dat de reële rechte overaftelbaar is
- Ik weet dat ik weet dat ik weet dat de reële rechte overaftelbaar is
- …
Niet erg opwindende zinnen maar daar gaat het niet om: er is een duidelijke procedure die voor elk natuurlijk getal n een zin Z(n) construeert. Dit is een voorbeeld van een recursieve definitie: als we een beginobject beschrijven en een recept aangeven om elk volgende object te maken dan beschouwen we de constructie als voltooid.
Voor elke deelverzameling U van deze verzameling {Z(n):n∈N} van zinnen bestaat er dus een zin waarvan de deelconjucten precies de zinnen uit U zijn. Dat geeft ons dan overaftelbaar veel zinnen.
Daarmee is het hek van de dam: we kunnen blijven doorgaan en elke deelverzameling van de nieuwe verzameling zinnen weer samensmeden tot een nieuwe zin. En weer, en weer, en weer, …
De conclusie van Langendoen en Postal is nu dat alle zinnen die we zo kunnen maken geen verzameling vormen. Hier komt de analogie met Cantor’s resultaten om de hoek kijken. Cantor bewees namelijk dat elke verzameling strikt meer deelverzamelingen heeft dan elementen. Als je dit toepast op `de verzameling van alle verzamelingen’ kom je in de knoop: de elementen van die `verzameling’ zijn precies zijn deelverzamelingen, maar dat kan niet omdat er meer deelverzamelingen dan elementen zijn. De entiteit `de verzameling van alle verzamelingen’ bestaat dus niet.
Dezelfde redenering is nu van toepassing op `de verzameling van alle zinnen in een natuurlijke taal’: elke deelverzameling bepaalt een zin en verschillende deelverzamelingen bepalen verschillende zinnen en dat druist in tegen de conclusie van Cantor: altijd strikt meer deelverzamelingen dan elementen.
Waarom Lariekoek?
Waarom denk ik dat dit lariekoek is? Dat heeft vooral te maken met de manier waarop Langendoen en Postal hun `bewijs’ presenteren. Daar is wiskundig veel op af te dingen. Maar deze post is al behoorlijk lang en ik bewaar mijn wiskundige opmerkingen, bijvoorbeeld over de bovengenoemde ordeningen daarom maar voor deel twee.
Recent Comments