
Posts in category Set Theory
Lariekoek? II
We gaan het artikel Sets and Sentences van D. Terrence Langendoen en Paul Postal opnieuw lezen. De vorige keer heb ik de inhoud beschreven; nu bekijken we die nogmaals, maar met een wiskundig oog.
Zoals vorige keer beschreven gaat het er in het artikel om te laten zien dat in een Natuurlijke Taal de mogelijke zinnen een zeer grote collectie vormen: te groot om `verzameling’ genoemd te mogen worden. We volgen de redenering stap voor stap.
De definitie van Co-ordinate compound constituent is vorige keer al schematisch weergegeven door het volgende plaatje:
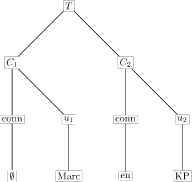
De top T is hier de co-ordinate compound constituent en de andere knopen zijn de conjucten waar T uit gevormd is. Die conjuncten bestaan uit een connectief en `constituent’. Ietwat simplistisch: T ontstaat door de constituents door middel van connectieven aan elkaar te plakken.
In punt (6) van het artikel wordt gedetailleerd beschreven hoe dat plakken in zijjn werk moet gaan, of preciezer: er wordt geformuleerd wat de relatie tussen de verzameling U van constituents en de compound T moet zijn. Uit die formulering zou je een plakmethode kunnen distilleren. Van punt (6) citeer ik deelpunt (d)
if two elements of U occur as subconjuncts of conjuncts C1 and C2 of T then C1 and C2 occur in a fixed order. Where C1 and C2 are of distinct length assume the shorter precedes; where C1 and C2 are the same length, assume some arbitrary order.
Als een student zoiets opschrijft trek ik mijn rode pen: ten eerste om het gebruik van `fixed’ en `arbitrary’ vlak achter elkaar, en ten tweede om dat `arbitrary’. Dat lees ik als “doe maar wat” en daar schrijf ik dus “Hoe dan?” bij. Ik kom straks nog op dit punt terug.
Verder in punt (6) wordt T een `co-ordinate projection’ van U genoemd en U de `projection set’ van U. Inderdaad: U is door T uniek bepaald maar niet andersom; het woord `arbitrary’ lijkt daar op te duiden.
Dan volgt een alinea waarin wordt beargumenteerd dat elke verzameling U een co-ordinate projection heeft. Dit zou `straightforward’ moeten zijn, volgens de schrijvers althans. Hier zijn de stappen (de `category Q’ die ter sprake komt is een niet nader gespecificeerde abstracte categorie van zinnen):
- Neem een verzameling U en laat k de kardinaliteit van U zijn (eindig of oneindig)
- Citaat:
Clearly, from the purely formal point of view, there is a co-ordinate compound W belonging to the category Q.
Dat klinkt mooi maar het heeft geen enkele bewijskracht; geen enkele rechtvaardiging, geen indicatie waar die W vandaan zou moeten komen. - Citaat:
Since there are no size restrictions on co-ordinate compounds, W can have any number, finite (more than one) or transfinite of immediate constituents.
Dit is slechte (wiskundige) stijl: eerst lijkt W vast, dan gaat hij alsnog variëren. Een betere formulering zou zijn: “er zijn co-ordinate compounds van alle mogelijke kardinaliteiten”. Die betere formulering maakt de bewering niet automatisch waar, er is nog steeds geen concrete rechtvaardiging gegeven. - Citaat:
W can then, in particular have exactly k such constituents.
Nogmaals: die vaste W is omgevormd tot een gepaste W. Niet mooi, maar vooruit dan maar. - De deelconjuncts van de conjuncts in W vormen een verzameling V die, volgens de regels in (6), kardinaliteit k heeft. Niks mis mee.
- Citaat:
To show that W is a co-ordinate projection of U, it then in effect suffices that there exist a one-to-one mapping from U to V.
Niet dus. Hoe je definitie (6) ook wendt of keert, dit haal je er niet uit. Wil W een co-ordinate projection van U zijn dan zal de verzameling V exact gelijk aan de verzameling U moeten zijn; een bijectieve afbeelding tussen die twee is echt niet genoeg. - Citaat:
But this is trivial, since the two sets have the same number of elements.
Dit klopt, maar ik verdenk de schrijvers ervan dat ze niet doorhebben wat hier achter zit. Georg Cantor definieerde `kardinaliteit’ op een manier die eigenlijk nietszeggend is, zie de tweede post in deze serie. Hij bewees daarna dat `hebben gelijke kardinaliteit’ equivalent is met `er bestaat een bijectieve afbeelding tussen’, maar tegenwoordig is dat laatste de definitie van het eerste.
Afsluiting
In het artikel formuleren Langendoen en Postal nu een afsluitingsprincipe. Na een waarschuwing dat niet elke co-ordinate projection noodzakelijkerwijs welgevormd is komt het volgende Closure Principle for Co-ordinate Compounding:
If U is a set of constituents each belonging to the collection, Sw, of (well-formed) constituents of category Q of any natural language, then Sw contains the co-ordinate projection of U.
Hoezo “the co-ordinate projection”? Uniciteit van die projecties is nog niet aan de orde geweest en over die collectie Sw is niet (expliciet) gezegd dat elke verzameling zinnen maar op één manier tot een grotere zin samen te voegen is.
Na een opmerking over het recursieve karakter van dit principe noemen de schrijvers de categorie S van zinnen als een categorie waarop het principe van toepassing is, althans: ze beweren dat (maar geven geen bewijs).
Dat weerhoudt ze er niet van het principe twee keer uit te spreken voor S. Eerst via een bijna letterlijke herhaling, met Q vervangen door S, en dan nog een keer met behulp van een formule(!): the co-ordinate projection van een verzameling U noteren we CP(U) en dan krijgen we
(∀U)(U⊂L → CP(U)∈L)
Hierin is L de collectie van alle elementen van de categorie S van een natuurlijke taal (voor mij betekent dat L=S want L en S hebben dezelfde elementen, maar er is misschien een subtiel verschil tussen de collectie van elementen van een categorie en de categorie zelf). Merk op dat hier het onbepaalde lidwoord definitief bepaald geworden is. Zonder het expliciet uit te spreken hebben de schrijvers kennelijk besloten dat compounding maar op één manier kan; de functienotatie CP(U) kan niet anders geïnterpreteerd worden.
Maar hoe is CP(U) gedefinieerd dan? Dat wordt niet duidelijk; een illustratie met met verzamelingen van drie, vier zinnen die tot één worden samengevoegd overtuigt mij niet.
Een soort van hierarchie
Dan komt eindelijk datgene waar ik al lang op zat te wachten: The Cantorian Analogue, waarin bewezen gaat worden dat de zinnen in een natuurlijke taal geen verzameling vormen. Overigens, een definitie van `verzameling’ hebben we nog niet echt gehad.
Het bewijs gaat aanvankelijk met gebruik van een verzameling zinnen als in de vorige post, de schrijvers gebruiken {Babar is happy; I know that Babar is happy; I know that I know that Babar is happy, …}. Die verzameling noemen ze S0.
Ik kort de zinnen even af: z0 is “Babar is happy” en, gegeven zn is zn+1 de zin “I know that zn“.
Onder de aanname dat de natuurlijke taal L aan het afsluitingsprincipe voldoet omvat L ook de verzameling S1 die bestaat uit S0 en de co-ordinate projections van de deelverzamelingen van S0 met twee of meer elementen. De formulering verdient het nauwkeurig gelezen te worden.
Then L also contains a set S1, made up of all the sentences of S0 together with all and only the co-ordinate projections of every subset of S0 with at least two elemente, that is, with a set containing one co-ordinate projection for each member of the power set of S0 whose cardinality is at least 2.
Deze zin deugt niet. De delen voor en na `that is’ spreken elkaar tegen. De eerste versie van S1 bevat alle co-ordinate projections van alle deelverzamelingen van S0 — de projecties van iedere deelverzameling —; de tweede versie bevat van elke deelverzameling (precies) één projectie. Daarnaast is de eerste versie uniek bepaald door het `all and only’, daar is `the set S1‘ dus meer op zijn plaats; in het tweede deel past `a set’ wel.
Je zou het meervoud `projections’ enkelvoud kunnen maken; dat sluit wat beter aan bij de formulering van de afsluitingeigenschap, the projection zou dan telkens de functiewaarde CP(U) kunnen zijn. Maar dan gaat het ook mis: vóór het `that is’ is de keuze van projectie duidelijk vastgelegd, maar na `that is’ zit er nog potentiële willekeur in de keuze van projectie, er staat niet expliciet dat die one projection ook echt CP(U) is.
De schrijvers geven dan een voorbeeld van hoe S1 er uit zou kunnen zien (dus toch geen welbepaalde verzameling):
{z0; z1; z2; …; z0 and z1; z0 and z2; …; z0, z1, and z2 …} (voor alle duidelijkheid: de punt-komma’s scheiden de zinnen en de komma’s dienen als connectieven in de zinnen).
Dan volgt een lange alinea waarin met veel omhaal van woorden de kardinaliteit van S1 wordt bepaald. Door het `één projectie per verzameling’ is dat niet moeilijk: dat is dezelfde kardinaliteit als die van de familie van alle deelverzamelingen van S0 en omdat S0 aftelbaar oneindig is, en dus kardinaliteit ℵ0 (alef-nul) heeft is die kardinaliteit gelijk aan 2ℵ0 (2-tot-de-macht-alef-nul) en niet ℵ1, zoals Langendoen en Postal opschrijven. Ergens bij hun bestudering van de verzamelingenleer is er iets misgegaan en is de Continuümhypothese waar geworden.
Zoals wellicht verwacht wordt dit proces voortgezet. Er komt een rij verzamelingen S0, S1, S2, …, netjes recursief gedefinieerd door Sn+1=Sn∪Kn. Hierbij is Kn telkens de verzameling projecties van deelverzamelingen van Sn. In formule
Kn={x:(∃y)(y⊆Sn ∧ x is the co-ordinate projection of y)}
Hier had dus ook Kn={x:(∃y)(y⊆Sn ∧ x=CP(y))} kunnen staan.
Op deze manier komt er een hierarchie van verzamelingen zinnen tot stand; die zinnen worden steeds complexer en de verzamelingen steeds groter. De schrijvers claimen onterecht dat voor elke n het kardinaalgetal van Sn gelijk is aan ℵn. De juiste formule is een machtsverheffing met een torentje van n tweeën, met bovenaan nog een ℵ0. Dat kardinaalgetal noteren we in de verzamelingenleer als ℶn (beth-n).
Dit verhaal culmineert in wat de schrijvers The NL Vastness Theorem noemen: Natural Languages are not sets.
Het bewijs verloopt uit het ongerijmde. Neem aan dat L een verzameling is. Het proces van co-ordinate projection definieert een injectieve afbeelding van de machtsverzameling van L naar L zelf. Dat kan niet volgens een stelling van Cantor: elke verzameling heeft strikt meer deelverzamelingen dan elementen. Tegenspraak.
Er is echter een groot MAAR, en daar gaan we het nu over hebben.
Ordeningen en lengten
Het `bewijs’ in het artikel staat vol met impliciete aannamen over het gedrag van verzamelingen die een niet-wiskundige waarschijnlijk niet zo snel zullen opvallen. Er zijn twee dingen die nogal schadelijk zijn voor de redenering zoals hierboven beschreven.
Ten eerste de ordening, ik heb er bij de beschrijving van de co-ordinate projection al op gezinspeeld: daar zit, op zijn zachtst gezegd, een onvolledigheid.
Die onvolledigheid duikt op bij de overgang van S1 naar S2, en nog erger bij de stap daarna van S2 naar S3.
Bij de eerste stap, van S0 naar S1, is er niets aan de hand: we hebben onze verzameling S0 genummerd en die nummering ordent elke deelverzameling van S0, waarmee zo’n deelverzameling een natuurlijke projectie heeft, ook als deze oneindig veel elementen heeft. Dit levert natuurlijk wel zinnen zonder einde op.
Daarna, van S1 naar S2, hebben we een probleem: er zijn (overaftelbaar) veel zinnen van oneindige lengte (allemaal even lang als de verzameling der natuurlijke getallen). Daar gaat het `fixed’ en `arbitrary’ van punt (6)(d) dus wringen. Hoe orden je zo’n verzameling zinnen? De heren Langendoen en Postal spreken zich daar niet over uit.
Gelukkig kunnen we hier de lexicografische ordening gebruiken: kijk naar het eerste teken (inclusief spaties) waar de zinnen verschillen en neem een besluit op basis van de ordening van de tekens. Zie ook de post Boekenplanken voor gevorderden waar een aspect van die ordening aan de orde komt dat hier de zaak ook compliceert: er zijn heel veel verzamelingen die de eigenschap hebben dat tussen elk tweetal zinnen oneindig veel zinnen staan en die ook geen eerste zin hebben. Als we die ordening gebruiken om projecties te maken dan krijgen we dus zinnen zonder begin, zonder einde, en met voegwoorden die gaan ten minste één kant niet zien wat ze verbinden.
Het kan nog erger. We kunnen de verzameling S2 opvatten als de familie van alle deelverzamelingen van de reële rechte R. En op die familie kan geen lineaire ordening gedefinieerd worden. Het sleutelbegrip is hier `definiëren’: er is geen formule die de familie deelverzamelingen van R zó sorteert dat elk tweetal verzamelingen vergelijkbaar is. De stap van S2 naar S3 kan eigenlijk niet genomen worden.
Ten tweede is er nog het begrip lengte van een zin. Cantor heeft een hele theorie van orde-typen (`lengten’) van lineair geordende verzamelingen ontwikkeld. Wat daar vooral opvalt is dat er veel onvergelijkbare orde-typen zijn. En die kom je ook tegen bij de stap van S2 naar S3: het voorsorteren op `lengte’ gaat dus ook al niet.
Welordeningen?
“Maar, er zijn toch welordeningen?”, hoor ik degenen die wat verzamelingenleer hebben bestudeerd opwerpen. Dat klopt, en we hebben ook nog Zermelo’s Welordeningsstelling, die zegt dat elke verzameling een welordening heeft. Bij een welordening zijn de elementen zo gesorteert dat elke deelverzameling (niet-leeg) een eerste element heeft. Welordeningen zijn ook nog onderling vergelijkbaar, dus die co-ordinate projections schrijf je zo op.
Inderdaad, maar die welordeningsstelling is equivalent met het Keuzeaxioma en daarmee hoogst niet-constructief. Zoals de verzameling S2 geen definieerbare lineaire ordening heeft heeft S1 geen definieerbare welordening.
Je kunt met welordeningen werken maar dan laat je de willekeur van het Keuzeaxioma binnen en daarmee ben elke zweem van een grammatica kwijt.
Ik weet niet of je dan nog van een natuurlijke taal kunt spreken.
Korte samenvatting
We zijn hier nog niet aan het einde van het artikel Sets and Sentences gekomen. Er gebeurt wiskundig niet veel nieuws meer en het derde deel beargumenteerd dat zo ongeveer alle theoriën over natuurlijke getallen uit de tijd van schrijven niet deug(d)en. De argumenten steunen op The NL Vastness Theorem.
In het bewijs van die stelling zitten gaten. En die gaten bestaan vooral uit ontbrekende definities en aannamen.
Zo wordt nergens echt vastgelegd wat een verzameling eigenlijk is; het dichtst bij een definitie komt men in het bewijs van de Vastness Theorem: het kenmerkende van een verzameling is dat deze een kardinaliteit, een `aantal elementen’, heeft. Dat is de omgekeerde wereld en ook niet echt nodig.
Cantor definieerde eerst `Menge’ en pas daarna `Machtigkeit’; naar moderne maatstaven hebben die definities weinig inhoud maar ze stuurden de intuïtie wel de goede kant op.
De manier waarop ik het `bewijs’ van de stelling heb opgeschreven laat zien dat die aanname over kardinaliteit vermeden kan worden; we hebben alleen goede afspraken over het hebben van meer, minder en evenveel elementen nodig en dat kan zonder die aantallen te definiëren of benoemen. Net als we geen eenheid van lengte nodig hebben om uit te maken of ik langer, korter, of even lang ben als Marc van Oostendorp: zet ons naast elkaar en je weet het.
Zoals al opgemerkt zijn de centrale noties van het artikel niet goed afgesproken; de definities lijken, gezien de gegeven voorbeelden, vooral ingegeven door de eindige situatie. Bij het suggestief opschrijven van de verzameling S1 zien we ook alleen maar eindige zinnen.
Ik vermoed dat niemand de schrijvers heeft gevraagd hoe men het zich moet voorstellen: een collectie zinnen die geordend is als de rationale getallen: zonder begin, zonder eind en met tussen elk tweetal zinnen ondindig veel andere. Hoe maak je daar een goedlopende zin van?
Boekenplanken voor gevorderden
In dit vervolg op deze blogpost ga ik het hebben over het ordenen van boeken.
Bij de twitterdiscussie over of er verschil is, of niet, tussen boeken en getallen kwam ook de mogelijkheid getallen en boeken te ordenen ter sprake. Hierbij werd met `getal’ stilzwijgend `natuurlijk getal’ bedoeld. Nu komen natuurlijke getallen met een natuurlijke ordening, waarin elk getal een directe opvolger heeft en elk getal, behalve het eerste, een directe voorganger.
Hoe zit het met de boeken? Als je het met Marc eens bent dat een boek van vijf miljard pagina’s meer dan genoeg is zijn we gauw klaar.
Nee, ik denk dat het redelijk is om te zeggen dat een boek een bepaalde maximale omvang heeft: iets van vijf miljard pagina's is niet langer een boek, maar een serie boeken.
— Marc van Oostendorp (@fonolog) October 15, 2019
Als we het aantal bladzijden begrenzen en niet raar doen met onhandelbaar grote pagina’s en ook niet al te kleine letters gebruiken dan is, in een vaste alfabet, het aantal boeken eindig. Als we de letters, spaties, interpunctie etc van een vaste ordening voorzien kunnen we elk boek als een rij symbolen beschouwen en gewoon lexicografisch ordenen: als rij/boek A een echt beginstuk van rij/boek B is dan komt boek A voor boek B; anders kijken we naar de eerste plek waar A en B verschillen en gebruiken de ordening van de tekens om te beslissen welke van de twee eerst komt. Het resultaat is een rij boeken met een eerste en een laatste, waarin elk boek behalve het eerste een directe opvolger heeft, en elk boek behalve het laatste een directe voorganger.
En dit laat inderdaad een praktisch verschil zien tussen getallen en boeken: van de laatste zijn er maar eindig veel.
Oneindig veel boeken
Echter, …, de hele discussie begon met een artikel van Paul Postal, waarin het begrip boek wat ruimer werd opgevat: elke eindige rij symbolen is een potentieel boek.
Dan wordt het ordenen van de boeken een minder eenvoudige klus. Er was een heel specifieke vraag van Marc:
Maar boeken kun je toch ook ordenen? Bijvoorbeeld alfabetisch (op de hele tekst)? Dus na een boek dat eindigt op 'vrede op aardbei' komt een boek dat verder identiek is, maar eindigt op 'vrede op aarde'?
— Marc van Oostendorp (@fonolog) October 15, 2019
Het antwoord daarop is niet geheel flauw.
Lexicografisch
Je kunt je (potentiële) boeken nog steeds als hierboven lexicografisch ordenen. Dan is in ieder geval duidelijk dat het antwoord op de vraag van Marc bevestigend luidt: zijn twee boeken zijn geen beginstukken van elkaar en ze verschillen als eerste bij de positie van de b en de d, en de b komt voor de d. Er zitten natuurlijk nog zat boeken tussen die twee: aardbei komt voor aardbeienjam en dat komt voor aardappel hetwelk zelf weer voor aarde komt.
Het interessante, zeker voor wiskundigen, is dat tussen elk tweetal boeken oneindig veel (potentiële) boeken staan.
Tussen de nogal flauwe boeken (a) en (b) staan (ab), (aab), (aaab), (aaaab), … (een dalende rij boeken); tussen (ab) en (aab) kun je ook zoiets maken: (aba), (abab), (abaab), …
Dit is voor makers van boekeplanken nogal vervelend: de planken moeten overal oneindig lang zijn om al die oneindig veel tussenliggende boeken kwijt te kunnen.
Iets praktischer
Het kan praktischer (ook al door Marc opgemerkt in een commentaar op neerlandistiek.nl: sorteer de boeken eerst op lengte en orden ze bij vaste lengte weer gewoon lexicografisch. Dan heb je een eerste boek en elk ander boek heeft net als bij de natuurlijke getallen een directe voorganger en een directe opvolger. Dit is wel zo praktisch voor de timmerlieden: terwijl jij de planken vult kunnen zij gewoon vooruit werken.
Het verschil met hierboven is wel dat het aarde-boek van Marc vóóor het aardbei-boek komt: het eerste is één karakter korter dan het tweede.
Kleene-Brouwer
Tijdens de discussie noemde ik nog de Kleene-Brouwerorde; die lijkt op de lexicografische met dit verschil dat indien A een echt beginstuk van B is A juist achter B geplaatst wordt. Het tweede deel van de definitie blijft ongewijzigd. Dus (a) komt nog steeds voor (b), maar (aaa) komt voor (aa) en die weer voor (a).
Ook dit is een nachtmerrie voor boekenkastmakers: tussen elk tweetal boeken hebben we weer oneindig veel boeken. Het is zelfs een dubbele nachtmerrie: lexicografisch is er tenminste een eerste boek, bij Kleene-Brouwer hebben we dat niet eens; de timmerlieden moeten nu twee kanten op planken ophangen die overal oneindig veel boeken moeten kunnen hebben.
Voor mensen die werken in Beschrijvende Verzamelingenleer en in de Recursietheorie is de Kleene-Brouwerordening heel nuttig. Maar dat is weer een heel ander verhaal.
Strictly between
This is the third in a short series of blog posts intended to explain the terms in red in the following sentence, that succinctly describes the Continuum Hypothesis.
There is no set whose cardinality is strictly between that of the integers and the real numbers.
These are, in the words of John Lloyd, the bits that he does not understand.
Thus far we have dealt with set in this post and this one, and with the notion of cardinality in this one.
To recap our findings: we first came to the disappointing realisation that the definitions proposed by Georg Cantor, very strictly speaking, did not deliver on their promises. There is a way out of this via the development of Axiomatic Set Theory but that would take us too far afield.
In the spirit of Cantor we can define a set to be a well-defined collection of objects as long as we furnish a good description/definition of that collection.
As to cardinality: we consider it a property that every set has and that leads to two derived properties of pairs of sets that are defined unambiguously.
Two sets, X and Y, are said to have the same cardinality if “it is possible to put them, by some law, in such a relation to one another that to every element of each one of them corresponds one and only one element of the other” (Cantor, translation by Jourdain). We simply abbreviate this as |X|=|Y|. Additionally we can define what |X|≤|Y| (“the cardinality of X is less than or equal to that of Y”) means that there is a subset Z of Y such that |X|=|Z| (“X has the same cardinality as some subset of Y”).
In this post there are some examples of sets with the same cardinality (provinces of the Netherlands, and months of the year) and with different cardinalities (two teaspoons of chocolate sprinkles).
It is now actually quite straightforward to come to the definition of strictly between. First we define `strictly less’; then `strictly between’ is a combination of twice `strictly less’.
In the example of the chocolate sprinkles the cardinality of the sprinkles in the left hand spoon was strictly less that the cardinality on the right hand side. I paired off the sprinkles on the left with a subset of the sprinkles on the right and it was at once clear that there was no way to pair off both sets with each other. In short, we saw that |L|≤|R| and that |L|≠|R|. And this will be our definition of “the cardinality of X is strictly less than that of Y”, in symbols |X|<|Y|: it is the conjuction of |X|≤|Y| and |X|≠|Y|.
Cantor’s seminal theorem from 1873 can be summarized as |N|<|R|, where N and R denote the sets of natural and real numbers respectively (more on the definition of these in later posts).
Since N is a subset of R it is clear that |N|≤|R|; the hard part of Cantor’s proof was to show that |N|≠|R|, i.e., that there is no way to pair off the natural numbers and the real numbers with each other.
So “the cardinality of Y is strictly between the cardinalities of X and Z” is the conjuction of |X|<|Y| and |Y|<|Z| and ultimately comes down to the following four statements:
- X can be put into one-to-one correspondentce with a subset of Y,
- Y can be put into one-to-one correspondentce with a subset of Z,
- X cannot be put into one-to-one correspondentce with Y, and
- Y cannot be put into one-to-one correspondentce with Z
For explicitly given sets it is often not too difficult to establish whether this state of affairs holds or not; certainly not with all the tools that Cantor and his followers have developed.
In the case of the Continuum Hypothesis matters lie differently: two of the three sets are there; one should produce the third in the middle, or show that no third exists. At the beginning of the 20th century either possibility probably seemed like an insurmountable task, although Cantor strongly believed in the second alternative.
Loterijen? Eerder de Lotto.
Gisteren, in het stuk over bijna-disjuncte families, heb ik het niet over de loterijen gehad waar het in stuk in NewScientist over ging. Sommige mensen waren benieuwd naar die metafoor voor het resultaat in het artikel van David Schrittesser en Asger Törnquist. Ik doe hier een poging zo’n loterij te beschrijven. Ik laat het aan de lezer om te beoordelen welke uitleg beter is: de feitelijke in de vorige post of de metaforische hieronder.
Om te beginnen: `loterij’ is eigenlijk een verkeerde vertaling van het Amerikaanse `lottery’. Bij een loterij koop je een lot en weet je niet wat je lotnummer zal zijn. In een lottery kies je zelf de getallen op je kaartje. Het is dus eerder te vergelijken met onze Lotto. De beschrijving van de `loterij’ in NewScientist is ook eerder die van een variant op de Lotto dan op de Staatsloterij.
Een oneindige variant op de Lotto
In plaats van 6 uit 45 kiezen we getallen uit N. Met de betekenis van het woord `bijna’ van gisteren in gedachten leggen we vast dat we niet `bijna niets’ en ook niet `bijna alles’ mogen kiezen: we moeten er oneindig veel kiezen (aankruisen) en we moeten er oneindig veel niet aankruisen.
Een `formulier’ heeft dus oneindig lange kolommen (net zo lang als N) en oneindig veel kolommen. Je mag dus, kennelijk, oneindig veel kolommen invullen. Wat in het stuk niet duidelijk vermeld wordt is hoe je een prijs kunt winnen.
Maar met het artikel in de hand kunnen we wel wat regels opstellen. Het artikel bewijst namelijk dat oneindige maximale bijna-disjuncte families niet bestaan (dat `oneindige’ heb ik gisteren voor het gemak weggelaten maar dat wordt nu belangrijk); het stukje zegt dat er geen winnende formulieren bestaan. Conclusie: een (zeker) winnend formulier heeft in de kolommen een oneindige maximale bijna-disjuncte familie.
Daaruit concluderen we dan dat een winnende kolom een oneindige doorsnede heeft met de getrokken deelverzameling van N.
We halen hier ook nog wat voorwaarden uit waaraan een geldig formulier aan moet voldoen: niet alleen mag je in één kolom niet bijna alle getallen aankruisen, ook mag je er niet voor zorgen dat je over een eindig aantal kolommen bijna alle getallen aankruist. Als je bijvoorbeeld over tien kolommen achtereenvolgens de tienvouden, tienvouden-plus-1, … tienvouden-plus-9 aankruist win je ook zeker; die tien verzamelingen vormen een eindige maximale bijna-disjuncte familie.
Samengevat: op je formulier kruis je in een aantal kolommen telkens oneindig veel getallen aan. Dat aantal kolommen mag eindig zijn maar hoe dan ook: in elke eindige greep kolommen mag je nooit samen bijna alle getallen aankruisen. Je wint als je in ten minste één kolom oneindig veel getrokken getallen hebt aangekruist.
Door je kolommen bijna-disjunct in te vullen spreid je je inzet het zuinigst; twee kolommen met een oneindige doorsnede hebben een grote overlap aan mogelijkheden. Ten slotte: als je kolommen een maximale bijna-disjuncte familie vormen dan bevat je formulier, per definitie, een winnende kolom.
Het bestaan van (zuinige) winnende formulieren
Het stuk in NewScientist vertelt niet de hele waarheid. De suggestie wordt gewekt dat winnende formulieren niet bestaan. Dat is slechts voor de helft waar. Je kunt bewijzen dat zeker winnende en zuinige formulieren bestaan, met behulp van het Lemma van Zorn (een equivalent van het Keuzeaxioma).
Sommige wiskundigen vragen zich in dit soort situaties af of het Lemma van Zorn wel nodig is bij zo’n concrete vraag; dat Lemma levert namelijk nogal zwaar geschut. En dat is nu wat David Schrittesser en Asger Törnquist hebben vastgesteld: je hebt zwaar geschut nodig; er is bestaat een situatie waarin dat zware geschut niet voorhanden is en waarin geen enkele maximale bijna-disjuncte familie bestaat.
Loterijen? Nou, nee.
Vanochtend (2019-09-19) vond ik via twitter dit artikel uit NewScientist (een vrij letterlijke vertaling van dit stuk. Nadat ik het verhaal over niet-bestaande oneindige loterijen had gelezen was ik nog niets wijzer geworden. Na doorklikken naar het originele artikel zag ik dat ik het al eerder had gezien in april, op ArXiV.org en dat het niets met loterijen te maken had.
Maar waar gaat het artikel dan wel over? Over bijna-disjuncte families. En wat zijn dat nu weer?
Eén van mijn favoriete objecten in de verzamelingenleer is de familie van alle deelverzamelingen van de verzameling N der natuurlijke getallen. Dit is een nimmer opdrogende bron van vragen en resultaten die in veel delen van de wiskunde gebruikt worden maar die gewoon ook leuk zijn om aan te werken.
Hierbij is het bijwoord `bijna’ bijna niet te vermijden. In het artikel waar we het hier over hebben past men `bijna’ dus toe op `disjunct’. Nu noemen we twee verzamelingen A en B `disjunct’ als hun doorsnede leeg is, A∩B=∅, als er geen x is die zowel in A als in B zit.
Het woord `bijna’ kort eigenlijk het wat uitgebreidere `op eindig veel na’ af: twee verzamelingen zijn bijna disjunct als hun doorsnede eindig is — `hun doorsnede is op eindig veel elementen na leeg’. Hierbij eisen we wel dat de verzamelingen zelf oneindig zijn want anders is bijna-disjunctheid niet zo spannend.
De twee verzamelingen E en O van respectievelijk de even en oneven getallen zijn disjunct; er is geen natuurlijk getal van tegelijk even en oneven is.
Hier is een mooie truc, van Sierpinski uit 1928: voor elk positief irrationaal getal x en voor elk natuurlijk getal n doen we het volgende: bepaal n×x, neem het gehele deel [n×x] (gooi alles achter de komma weg) en deel dat weer door n.
Bij vaste x krijg je zo een rij rationale getallen: [x], [2x]/2, [3x]/3, [4x]/4, … Bij π bijvoorbeeld krijgen we zo 3, 3, 3, 3, 3, 3, 3, 25/8, 28/9, 31/10, 34/11, 37/12, …
Uit de definitie van de rij volgt dat 0<x-[n×x]/n<1/n voor alle n en dit betekent iets voor de bijbehorende verzamelingen termen. Bij elke x stoppen we de termen van de rij in de verzameling Sx, dus Sπ={3, 25/8, 28/9, 31/10, 34/11, 37/12, …}.
Neem nu eens twee irrationale getallen x en y met x<y; dan geldt voor n>1/(y-x) dat [n×y]/n>y-1/n>x, en dus zit [n×y]/n niet in Sx. We concluderen dat de verzamelingen Sx en Sy bijna disjunct zijn.
De verzamelingen Sx vormen het soort familie waar het artikel over gaat: een bijna-disjuncte familie, elk tweetal elementen is bijna disjunct (en elke Sx heeft oneindig veel elementen).
Het voorbeeld van Sierpinski laat zien dat er een groot verschil is tussen `disjunct’ en `bijna disjunct’. Als een familie disjunct is dan zit elk punt in ten hoogste één element van de familie. De bijna-disjuncte familie van Sierpinski bestaat uit verzamelingen rationale getallen, daar zijn er evenveel van als natuurlijke getallen. De familie zelf heeft evenveel elementen als er positieve irrationale getallen en dat zijn er veel en veel meer als er natuurlijke getallen zijn (en dat is allemaal precies te maken). Dat zorgt er voor dat veel van de rationale getallen in meer dan één verzameling Sx zitten.
Maar goed, terug naar het artikel. Het hoofdresultaat zegt iets over de aard van bijna-disjuncte families deelverzamelingen van N: onder bepaalde omstandigheden is er geen maximale bijna-disjuncte familie. Als je zo’n familie hebt kun je er een oneindige deelverzameling van N bij doen zó dat de grotere familie ook bijna-disjunct is (en nog één, en nog één, …).
Wat dit nou met loterijen te maken heeft? Ik zou willen zeggen dat ik geen idee heb maar dat heb ik wel. Ik vind de vergelijking echter zó vergezocht dat ik de lezer er niet mee lastig wil vallen. En ik denk eigenlijk dat de uitleg van die vergelijking lastiger is dan die van het resultaat zelf.
Upgoer Five
Today I was reminded of the Upgoer Five Editor, which was inspired by this XKCD cartoon (an explanation of the workings of the Saturn V rocket in very simple words).
I knew I had tried it once and thanks to twitter I could find my `explanation’ of bijections and a `definition’ of infinity again. This is just a short post so that I have an obvious place to look for the link to that short piece, when I need it.
Also, it will be fun to do this in Norwegian.
What is cardinality?
This is the second in a short series of blog posts intended to explain the terms in red in the following sentence, that succinctly describes the Continuum Hypothesis.
There is no set whose cardinality is strictly between that of the integers and the real numbers.
These are, in the words of John Lloyd, the bits that he does not understand.
In the first post and its addendum we dealt with the difficulty that any definition of the notion `set’ must, to some extent, be circuitous: one cannot avoid the use of a synonym, such as `collection’, `aggregate’, …
The next term in red in the sentence above is `cardinality’. Here the difficulty is worse.
To see why this is we turn to Georg Cantor again in his Beiträge zur Begründung der transfiniten Mengenlehre he gave the following definition.
,Mächtigkeit` oder ,Cardinalzahl` von M nennen wir den Allgemeinbegriff, welcher mit Hülfe unseres activen Denkvermögens dadurch aus der Menge M hervorgeht, dass von der Beschaffenheit ihrer verschiedenen Elemente m und von der Ordnung ihres Gegebenseins abstrahirt wird.
Das Resultat dieses zweifachen Abstractionsacts, die Kardinalzahl oder Mächtigkeit von M, bezeichnen wir mit |M|.
In the translation by Philip E. B. Jourdain this becomes
We will call by the name “power” or “cardinal number” of M the general concept which, by means of our active faculty of thought, arises from the aggregate M when we make abstraction of the nature of its various elements m and of the order in which they are given.
We denote the result of this double act of abstraction, the cardinal number or power of M by |M|.
As beautiful as this may sound it is actually meaningless. The phrases “active faculty of thought” and “abstraction of the nature” have no mathematical meaning. When one reads the next few pages of Cantor’s paper it becomes quite clear that this is an attempt to define `the number of elements’ of the set. Those next pages establish that two sets have the same power if and only if “it is possible to put them, by some law, in such a relation to one another that to every element of each one of them corresponds one and only one elemen of the other” (translation by Jourdain).
By way of example the sets of provinces of the Netherlands and of months of the year have the same power; the following relation between provinces and months establishes this:
(January,Groningen),
(February,Drente),
(March,Friesland),
(April,Overijssel),
(May,Flevoland),
(June,Gelderland),
(July,Utrecht),
(August,Noord-Holland),
(September,Zuid-Holland),
(October,Zeeland),
(November,Noord-Brabant),
(December,Limburg).
Every month corresponds to one and only one province and every province corresponds to one and only one month.
Before we continue: `cardinality’ is just another term for `power’.
The definition of power, or cardinality, or cardinal number is more incomplete than that of `set’. At least in the latter definition we had a synonym to fall back on; the definition of cardinality does not even have that contingency. However, and this is very important for what follows, even though `cardinality’ does not have a good definition the notion that two sets have the same cardinality does have a mathematically sound and workable definition: nowadays Cantor’s characterization of when two sets have the same power is taken as its definition.
As an aside: a similar thing can be said of the notion of length. If we ever come face to face it will be clear immediately whether the length of John Lloyd is larger or smaller than mine (or equal even) but unless we happen to have a tape measure handy we will not know our lengths, expressed in the local units.
Small children know how to compare the cardinalities of sets: a practical instance is given by chocolate sprinkles, a favourite Dutch breakfast item. If one takes two spoonfuls of these items it is quite easy to check whether these contain the same number of sprinkles. Here are two heaps of them:

I personally did the following: take one from each heap and eat them, and again, and again, and again, … after a while the … was empty and the other one was not. This means that the heaps did not contain the same number of sprinkles and I we can even say that the cardinality of the other heap of sprinkles was larger than that of the … one. This process was quite easy I could walk away and resume again later; I did not worry about losing my count because I did not count.

Thus we find ourselves in the strange situation that we have an undefined notion `cardinality of a set’, yet when we are given two sets we have a way of potentially deciding whether they have the same cardinality. We can even say when the cardinalities of two sets are comparable: if M has the same cardinality as some subset of N we can express this by saying that the cardinality of M is less than or equal to that of N, we can even write |M|≤|N| in that case. In the next installment we shall see that the next bit, strictly between, actually does have an unambiguous definition.
What is a set? (revisited)
This is an addendum to the first in a short series of blog posts intended to explain the terms in red in the following sentence, that succinctly describes the Continuum Hypothesis.
There is no set whose cardinality is strictly between that of the integers and the real numbers.
These are, in the words of John Lloyd, the bits that he does not understand.
The gist of the post referred to above was that, very strictly speaking, sets have no proper mathematical definition. The definitions that were quoted from the works of Bolzano and Cantor were, to a large extent, by synonym: “a set is a collection …”. The ellipsis would contain some conditions what the collection should satisfy to be deemed a set. But the definition would be incomplete because `collection’ remained undefined. Many definitions in mathematics suffer from a similar `defect’: at some point there is a primitive notion that is not further defined. In most every branch of mathematics that primitive notion turns out to be `set’ in some form or another.
That looks bad: Mathematics seems to be based on a badly defined notion. However not all is lost. Most of the time we know exactly what we are talking about. It is true that `collection’ is undefined but, as mentioned in the original post, we recognize one when we see one and in Mathematics we are very particular about how we work with them.
By way of example consider the books currently in our house. They form a well-defined collection: it is very clear which books are in that collection and which books are not. That collection forms what Bolzano and Cantor consider to be a set. It has an unambiguous definition. Just like the set of books in our house that have exactly 250 pages: everyone that we to gather `the books with exactly 250 pages’ will come back with the same collection. And the unambiguity separates the sets from the arbitrary collections. If I were to ask John Lloyd to gather the interesting books in our house he would most likely come out with a different collection than I would. The phrase `the interesting books in our house’ does not define a set.
What determines a set in mathematics is the unambigiuty of its definition: no matter who we set the task of determining what is in it, the answer should always be the same. That does not mean that that task is easy or doable in a (very) short time. The prime numbers form a set, a subset of the set of natural numbers, and for every individual natural number it is straightforward to determine whether it is prime or not, but separating them from the other natural numbers by hand is not an option.
Because of this and other examplese have developed the curly-braces notation for sets.
P = {n : n is a prime number}
is a properly defined set and for every natural number n we can decide whether n∈P (`n is in P’) or not.
And that is how mathematicians consider sets: as collections where membership can be checked unambiguously. Thus the advisoy committee of Episode 2, series 10 of the Museum of Curiosity forms a set, the funny members of that committee most likely do not. There is, alas, no unambiguous definition of `funny’.
What is a set?
This is the first in a short series of blog posts intended to explain the terms in red in the following sentence, that succinctly describes the Continuum Hypothesis.
There is no set whose cardinality is strictly between that of the integers and the real numbers.
These are, in the words of John Lloyd, the bits that he does not understand.
Sets pervade mathematics. Basically every definition of a mathematical structure contains the phrase “… a set such that …”. The language and tools of Set Theory generally make it possible to formulate results efficiently.
It may therefore come as a bit of a surprise that the question “What is a set?” does not have a straightforward answer. That sounds strange because we generally recognise a set when we see one: thimbles, forks, railway-shares …,(but not care, hope and soap) you name it, someone will have a set (collection) of it.
However, in Mathematics we like precise definitions, so that at every moment it is clear what we are talking about. A word of warning is needed here, nicely illustrated by this quote from Goethe.
1005. Die Mathematiker sind eine Art Franzosen; redet man mit ihnen, so übersetzen sie es in ihre Sprache, und dann ist es alsobald ganz etwas anderes.
Johann Wolfgang von Goethe, Maximen und Reflexionen, Nachlass, Über Natur und Naturwissenschaft
I do not have the illusion to know what Goethe actually meant to say with this and further study of his work may reveal that, but for me this quote is very apt all by itself. Many definitions of mathematical notions do not conform to the expectations of non-mathematicians. Things that are nigh on synonymous in the dictionary may have rather different meanings in mathematics.
To define what a set is we turn to two pioneers of the study of the infinite, Bernard Bolzano and Georg Cantor.
In his Paradoxieen des Unendlichen Bolzano wrote this on page 4, after a short introduction wherein he exlained the need for a definition of Menge.
Einen Inbegriff, den wir einem solchen Begriffe unterstellen, bei dem die Anordnung seiner Teile gleichgültig ist (an dem sich also nichts für uns Wesentliches ändert, wenn sich bloß diese ändert), nenne ich eine Menge;
In the translation of this work by Donald A. Steele and the above definition is rendered as follows.
An aggregate whose basic conception renders the arrangement of its members a matter of indifference, and whose permutation therefore produces no essential change from the current point of view, I shall call a set (Menge),
The very first words written by Georg Cantor in his Beiträge zur Begründung der transfiniten Mengenlehre are
Unter einer ,Menge` verstehen wir jede Zusammenfassung M von bestimmten wohlunterschiedenen Objecten m unserer Anschauung oder unseres Denkens (welche die ,Elemente` von M genannt werden) zu einem Ganzen.
In Zeichen drücken wir dies so aus:
M={m}
In the translation by Philip E. B. Jourdain we find:
By an “aggregate” (Menge) we are to understand any collection into a whole (Zusammenfassung zu einem Ganzen) M of definite and separate objects m of our intuition or our thought. These objects are called the “elements” of M.
In signs we express this thus:
M={m}
I think it is no coincidence that the notion `Menge’ was defined during investigations of the notion of `infinite’. At that moment the relations between the individuals that make up the whole are of secondary importance. And at some point one chooses one out of many synonyms &mdsah; collection, multitude, Mannigfaltigkeit, aggregate, set, verzameling, &hellip — and that becomes that name of the basic object of investigation.
If you read the definitions closely then you will see that they, strictly speaking, define nothing: both use a synonym, Inbegriff or Zusammenfassung, as a definition. However, Bolzano explicitly adds a condition (and Cantor does so implicitly, as witnessed by the rest of his paper) that was also mentioned above: the relations, if any, between the elements of the sets are not important. A few paragraphs before the definition Bolzano used the example of a broken tumbler; we tend to view that as different from that same tumbler before it was broken because the relations between the constituents have changed, as a set — of atoms, molecules — it has not changed.
It is this condition that tell us what the goal of Bolzano and Cantor undoubtedly was: delineate as sharply as possible about which objects they make their pronouncements. Bolzano’s definition was the summary of a long run-up where he discussed what properties a Menge should have. Cantor jumped right in because he had been considering sets for two decades already.
On a naïve level these definitions are quite workable because all that happens is that certain entities now have the label `set’ applied to them. Something like {1,2,3,4,5} is recognised by everyone as a “the set of natural numbers from 1 through 5”. And also sets with a description like {n ∈ N : n ≤ 10100} is fine, provided we have learned some of the language of mathematics. Here ∈ means `is element of’, ≤ means `less than or equal’ and N represents the set of natural numbers.
Mathematics differs from `daily life’ in one seemingly innocuous point: mathematicians give set status to a few things that some people do not recognise as sets. The empty set and sets with (exactly) one element are perfectly acceptable mathematically. But, if I were to tell you that I have a set of stamps and show you an album without any in it you would not consider me a stamp collector, nor if a were to show you just one stamp (right before I stick it on an envelope).
Mathematically speaking these are legitimate sets and they are also quite necessary because it would become quite cumbersome to exclude them as results of operations on sets. Think of equations. Very often we speak of solution sets and that would suddenly be illegal is the equation had no or just one solution? Really?
But still, this all assumes that we recognize a set when we see one: a collection of things thrown together between curly braces for a certain purpose. It’s the thirteen cards in your hand at bridge before you inspect and order them; it’s the points on a line where it is immaterial which point lies to the left or right of another point. All this does not tell us what a set is. For that we should define first what a collection is …
So, where does that leave us? The tools and language of Set Theory pervade mathematics and are quite powerful, yet we do not have a fully satisfactory definition of what a set actually is. For day-to-day mathematics that is no big problem because, as I said above, we recognise many familiar entities as `sets’ and treat them as such.
But what about those of us who want to know what a set really is? Who do not want to `recognise a set when they see it’? Well, we can satisfy them by setting up Set Theory purely logically and thus define what our objects are. The resulting `sets’ are not quite like those we learned to recognise but every one of our familiar sets has a faithful logical copy. This means that we can, with a bit of care, keep on using sets in the naïve way we have always done.
We may come back to that logical approach in a later post.
More on machine learning and CH
A few days ago I wrote about a paper establishing an independence result in the field of machine learning. Here I offer a few more comments.
In the paper the authors comment on the relation between their result and actual machine learning. That relation may seem tenuous because none of the functions involved in the arguments is related to any kind of algorithm.
Indeed the constructions of the compression schemes are very non-constructive in that they use repeated applications of the Axiom of Choice.
Now the inequality 2ℵ0>ℵω implies there are no compression schemes whatsoever. But it may be of interest to know that consistent examples of compression schemes must be nonconstructive. It turns out that, with the aid of a few standard results from Descriptive Set Theory it is relatively easy to show outright that there are no Borel measurable monotone compression schemes and hence no Borel measurable learning functions for the class of problems studied in the paper mentioned above either.
The details can be found in this note.
Recent Comments